2 Kotlin 基础
2.1 基本要素: 函数变量
2.1.3 变量
可变变量和不可变变量
- val–不可变引用。使用val声明的变量不能在初始化之后再次赋值。它对应的是java中的final变量
- var–可变引用。这种变量的值可以被改变。这种声明对应的是普通(非final)变量

👆在定义了val变量的代码块期间,val变量只能进行唯一一次初始化。但是,如果编译器能确保只有唯一一次初始化语句会被执行,可以根据条件使用不同的值来初始化它。
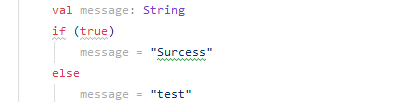
自身不可变(只可以执行一次,初始化一次)
注意,尽管val引用自身是不可变的,但是它指向的对象`可能`是可变的。列如
val languages = arrayListOf("Java")
lenguages.add("Kotlin")2.3 表示和处理选择:枚举和“when”
2.3.1 声明枚举类
什么是枚举
为了让编译器能够自动检查某个值在枚举的集合中,并且,不同用途的枚举需要不同的类型来标记,不能混用,我们可以使用 enum 来定义枚举类。
enum class Color{
RED,ORANGE,YELLOW,GREEN,BLUE,INDIGO,VIOLET
}kotlin 中 enum 是一个所谓的软关键词:只有当它出现在class前面时才会有特殊的意义,在其他地方可以把它当作普通的名称使用。
2.3.5 智能转换:合并类型检查和转换
kotlin智能转换的案例
表达式类型层次
interface Expr
class Num(val value: Int) : Expr // 简单的值对象类,只有一个属性value,实现了Expr接口
class Sum(val left: Expr, val right: Expr) : Expr // Sum运算的实参可以是任何Expr:Num 或者 Sum对表达式求值
fun eval(e: Expr): Int {
if (e is Num) {
// val n = e.value as Num //显示的转换为Num类型多余的
return e.value
}
if (e is Sum) {
return eval(e.left) + eval(e.right) // 变量 e 被智能的转换了类型
}
throw IllegalArgumentException("test")
}
结果

“is” 修饰符
在 kotlin 中,你要使用 is 检查来判断一个变量是否是某个类型。
什么时候进行智能转换?
如果你检查过一个变量是某种类型,后面就不再需要转换它了,可以就把它当作你检查过的类型使用。事实上编译器为你执行了类型转换,我们把这种行为称为 智能转换。
3 函数的定义与调用
用于处理集合、字符串和正则表达式的函数
使用命名参数、默认参数,以及中辍调用语法
通过扩展函数和属性来适配Java库
使用顶层函数、局部函数和属性架构代码
至此,就像使用Java一样,你应该可以自如地使用Kotlin了。可以看到,从Java到Kotlin,它们的很多概念是相似的,而往往Kotlin可以让它们更加简洁并易读。
在这一章中,你将看到Kotlin改进每个程序的一个重要环节:函数的声明与调用。我们还将研究,如何通过扩展函数将Java库转换为Kotlin风格,以在混合语言的项目中获得Kotlin的全部好处。
为了让讨论更有用和具体,我们将把Kotlin集合、字符串和正则表达式作为重点问题领域。作为例子,我们来看看如何在Kotlin中创建集合。
3.1 在Kotlin中创建集合
在开始学习对集合的各种有趣的操作之前,需要先学习会怎样创建它们。之前使用setOf函数创建了set。当时创建了一组颜色,现在,让我们保持它简单的同时,也支持数字。
val set = hashSetOf(1,7,53)可以用类似的方法创建一个list或者map:
val list = arrayListOf
val list = arrayListOf(1,7,53)
val map = hashMapOf(1 to "one",7 to "seven",53 to "fifty-three")这里的同并不是特殊的结构,而是普通的函数。稍后会探讨它。你能猜到这里创建的对象类型吗?
println(set.javaClass) //等价于Java中的getClass()
println(list.javaClass)
println(map.javaClass)
/* 本章代码都按照这种形式运行 */
fun main() {
val set = hashSetOf(1, 7, 53)
val list = arrayListOf(1, 7, 53)
val map = hashMapOf(1 to "one", 7 to "seven", 53 to "fifty-three")
println(set.javaClass) //等价于Java中的getClass()
println(list.javaClass)
println(map.javaClass)
}
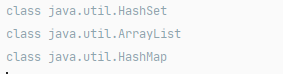
如你所见,Kotlin没有采用它自己的集合类,而是采用的标准的Java集合类,这对Java开发者是一个好消息。你现在所掌握的所有Java集合的知识在这里依然使用。
为什么Kotlin没有自己专门的集合类呢?那是因为使用标准的Java集合类,Kotlin可以更容易与Java代码交互。当从Kotlin中调用Java函数的时候,不用转换它的集合类来匹配Java的类,反之亦然。
尽管Kotlin的集合类和Java的集合类完全一致,但kotlin还不止于此。举个例子,可以通过以下方式来获取一个列表中的最后一个元素,或者是得到一个数字列表的最大值:
val strings = listOf("first", "second", "fourteenth")
println(strings.last())
val number = setOf(1, 14, 2)
println(number.max())
本章将会仔细研究它的工作原理,以及Java类上新增的方法从何而来。
在后续的章节中,我们开始讨论lambda时,你将会见识到更多的对于集合的操作,但是目前,就继续保持采用Java标准的集合类。6.3章节中会学习到集合类在Kotlin类型系统中的表示。
3.2 让函数更好调用
现在你已经知道了如何创建一个集合,让我们再来做点别的:打印它的内容。
Java的集合都有一个默认的toString实现,但是它格式化的输出是固定的,而且往往不是你需要的样子:
fun main() {
val list = listOf(1, 2, 3)
// 出发toString
println(list)
}
假设你需要用分号来分割每一个元素,然后用括号括起来,而不是采用默认实现用的方括号:(1;2;3)。要解决这个问题,Java项目会使用第三方的库,比如Guava和Apach Commons,或者在这个项目中重写打印函数。在Kotlin中,它的标准库中有一个专门的函数来处理这种情况。
本节你将自己实现这个函数。不借助Kotlin的工具来简化函数声明,从直接重写实现函数开始,然后再过度到Kotlin更惯用的方法来重写。
下面的joinToString函数就展示了通过在元素中间添加分隔符号,在最前面添加前戳,在最末尾添加后戳的方式把集合的元素逐个添加到一个StringBuilder的过程。
/*joinToString()的基本实现*/
fun <T> joinToString(
collection: Collection<T>,
separator: String,
prefix: String,
postfix: String
): String {
val result = StringBuilder(prefix)
for ((index, element) in collection.withIndex()) {
// 不用在第一个元素前添加分隔符
if (index > 0) result.append(separator)
result.append(element)
}
result.append(postfix)
return result.toString()
}
这个函数是泛型:它可以支持元素为任何类型的集合。这里泛型的语法和Java类似。
我们来验证一下,这个函数运行起来是不是像我们设想的那样:
fun main() {
val list = listOf(1, 2, 3)
println(joinToString(list, ";", "(", ")"))
}
看来这个函数是可行的。
3.2.1 命名参数
我们要关注的第一个问题就是函数的可读性。例子,看看joinToString的调用:
joinToString(collection,"","",".")你能看出这些String都对应的什么参数吗?这个集合的元素用空格还是点号来分割的?如果不去查看函数的声明,我们很难回答这个问题。或许你记住了这个声明,又或许你可以借助你的IDE,但从调用代码来看,这依然很隐晦
表明名称 对于Boolean类型的标志,这个问题尤其明显。为了解决这个问题,一些Java编程风格,推荐尝试enum类型而不是采用Boolean;而另外一些风格,会通过让你添加注释,在注释中指明参数的名称,例如:
joinToString(collection, /* separator */ "",/* prefix */"",/* postfix */".");在Kotlin中,可以做到更优雅:
joinToString(collection,separator = "",prefix = " ",postfix = ".")但调用Kotlin定义的函数时,可以显式的标明一些参数的名称。如果在调用一个函数时,指明了一个参数的名称,为了避免混淆,那它之后的所有参数都需要表明名称。
当你在重命名函数的参数时,IntelliJ IDEA 可以帮助你调用该函数的地方,一同更新命名参数。不过需要注意的是,要确保在重命名的时候,是采用的IDEA自带的Rename(重命名)或者ChangeSignature(改变函数签名)来处理,而不是手动地修改参数名称。
警告:
不幸的是,当你调用Java函数时,不能采用命名函数,不管是JDK中的函数,或者是Android框架的函数,都不行。把参数名称存到.class文件Java8及其更高版本的一个可选功能,而Kotlin需要保持和Java6的兼容性。所以,编译器不能识别出调用函数的参数名称,然后把这些参数名对应到函数的定义的地方。
3.2.2 默认参数值
Java的另一个普遍存在的问题是,一些类的重载函数实在太多了。只要看一眼java.lang.Thread以及它对应的八个构造方法( http://mng.bg/4KZC ),能让人够受了!这些重载,原本是为了向后兼容,方便一些API的使用者,又或者出于别的原因,但导致的最终结果都是一致的:重复。这些参数名和类型被重复了一遍又一遍,如果你是一个良好的公民,还必须在每次重载的时候重复大部分的文档。与此同时当你调用了一个省略了部分参数的重载函数时,你可能会搞不清它们到底用的哪个。
使用默认参数值减少重载在Kotlin中,可以在声明函数的时候,指定参数的默认值,这样就可以避免创建重载的函数。让我们尝试改进一下前面的joinToString函数。在大多数情况下,字符串可以不加前戳或者后戳并用逗号分割。所以我们把这些设置为默认值。
fun main() {
val list = listOf(1, 2, 3)
println(joinToString(list, ",", "", ""))
println(joinToString(list))
println(joinToString(list, ";"))
}
/*joinToString()的基本实现*/
fun <T> joinToString(
collection: Collection<T>,
separator: String = ",",/*有默认值的参数*/
prefix: String = "",
postfix: String = ""
): String {
val result = StringBuilder(prefix)
for ((index, element) in collection.withIndex()) {
if (index > 0) result.append(separator)
result.append(element)
}
result.append(postfix)
return result.toString()
}

当使用常规的调用语法时,必须按照函数声明中定义的参数顺序来给定参数,可以省略的只有排在末尾的参数。如果使用命名参数,可以省略中间的一些参数,也可以以你想要的任意顺序给定你需要的参数:
println(joinToString(list, postfix = ";",prefix = "# "))
注意,参数的默认值是被编码到被调用的函数中,而不是调用的地方。如果你修改了参数的默认值并重新编译这个函数,没有给参数重新赋值的调用者,将会开始使用行的默认值。
默认值和Java
考虑到Java没有参数默认值的概念,当你从Java中调用Kotlin函数的时候,必须显式地指定所有参数值。如果需要从Java代码中做频繁的调用,而且希望他能对Java的调用者更加便捷,可以使用@JvmOverloads注解它。这个指示编译器生成Java重载函数,从最后一个开始省略每个参数。
举个例子,如果用@JvmOverloads注解joinToString,编译器就会生成如下的重载函数:
String joinToString(Coollection<T> collection,String separator,String prefix,String postfix); String joinToString(Coollection<T> collection,String separator,String prefix); String joinToString(Coollection<T> collection,String separator); String joinToString(Coollection<T> collection);每个重载函数的默认参数值都会被省略。
3.2.3 消除静态工具类:顶层函数和属性
Java作为一门面向对象的语言,需要所有的代码都写作类的函数。大多数情况下,这种方式还能行得通。但事实上,几乎所有的大型项目,最终都有很多的代码并不能归属到任何一个类中。有时一个操作对应两个不同的类的对象,而且重要性相差无几。有时存在一个基本的对象,但你不想通过实例函数来添加操作,让它的API持续膨胀。
结果就是,最终这个类将不包含任何的状态或者实例函数,而且仅仅作为一堆静态函数的容器。在JDK中,最合适的例子应该是Collection了,看看你自己的代码,是不是也有一些类本身的Util作为后戳命名。
无需创建工具类 在Kotlin中,根本不需要去创建这些意义的类。相反,可以把这些函数直接放到代码文件的顶层,不用从属于任何类。这些放在文件顶层的函数依然是包类的成员,如果你需要从包外访问它,这需要import,但不需要跟外包一层。
让我们来把joinToString直接放到strings的包中试一下。创建join.kt的文件:
/*声明 joinToString作为顶层函数*/
package strings
fun joinToString(...):String{
...
}创建顶层函数 这些如何运行?当你编译这个文件的时候,会生成一些内,因为JVM只会执行类中的代码。当你使用Kotlin的时候,知道这些就够了。但是,如果需要从Java中来调用这些函数,你就必须理解它将会怎样被编译。为了方便理解,查看一段Java代码,这里会编译成相同的类:
/* Java */
package strings;
public class JoinKt{
public static String joinToString(...){...}
}可以看到Kotlin编译生成的类的名称,对应包含函数的文件的名称。这个文件中的所有顶层函数编译为这个类的静态函数。因此,但从Java调用这个函数的时候,和调用任何其他静态函数一样非常简单:
/* java */
import strings.JoinKt;
...
JoinKt.joinToString(list,"","","");
修改文件类名
要修改包含Kotlin顶层函数的生成类的名称,需要为这个文件添加@JvmName的注解,将其放在这个文件的开头,位于包名的前面:
@file:JvmName("StringFunction") //注解指定包名 package strings //包的声明跟在文件注解之后 fun joinToString(...):String{...}现在可以这样调用这个函数:
/* Java */ import strings.StringFunctions StringFunctions.joinToString(list,"","","");
顶层属性
和函数一样,属性也可以放在文件的顶层。在一个类的外面保存单独的数据片段虽然不常用,但还是有它的价值。
例子,使用var属性来计算一些函数被执行的次数:
var opCount = 0 //声明一个顶层属性
fun performOperation(){
// 改变该属性的值
opCount ++
//...
}
fun reportOperationCount(){
println("Operation performed $opCount times") //读取属性值
}像这个值将会被存储到一个静态的字段中。
也可以在代码中用顶层属性来定义常量:
val UNIX_LINE_SEPARATOR = "\n"默认情况下,顶层属性和其他任意的属性一样,是通过访问器暴露给Java使用(如果是val就只有一个getter,如果是var就对应一对getter和setter)。暴露给Java调用时这样 为了方便使用,如果你想要把一个常量public static final的属性暴露给Java,可以用const修饰它(这个适用于所有的基本数据类型的属性,以及String类型)。
const val UNIX_LINE_SEPARATOR = "\n"等同于Java代码
/* Java */
public static final String UNIX_LINE_SEPARATOR = "\n"3.3 给别人的类添加方法:扩展函数和属性
使用扩展函数场景 Kotlin的一大特色,就是可以平滑地与现有代码集成。甚至,纯Kotlin的项目都可以基于Java库构建,如JDK、Android框架,以及其他的第三方框架。当你在一个现有的Java项目中集成Kotlin的时候,依然需要面临现有代码目前不能转成Kotlin,甚至将来也不能转成Kotlin的局面。当使用这些API的时候,如果不用重写,就能使用到Kotlin为它带来方便,岂不是更好?这里,可以用扩展函数来实现。
定义一个扩展函数 理论上,扩展函数非常简单,它就是一个类的成员函数,不过定义在类的外面。为了方便阐释,让我们添加一个方法,来计算一个字符串的最后一个字符:
fun String.lastChar(): Char = this.get(this.length - 1)你所要做的,就是把你要扩展的类或者接口的名称,放到即将添加的函数前面。这个类的名称被称为接收者类型;用来调用这个扩展函数的对象,叫做接收者对象,如下

可以像调用类的普通成员函数一样去调用这个函数:
fun main() {
println("Koltin".lastChar())
}
在这个例子中,String就是接收者类型,而“Kotlin”就是接收者对象。
从某种意义上来说,你已经为String类添加了自己的方法。即使字符串不是代码的一部分,在没有类的源代码,你仍然可以在自己的项目中根据需要去扩展方法。不管String类是Java、Kotlin,或者像Groovy的其他JVM语言编写的,只要是它的编译为Java类,你就可以为这个类添加自己的扩展。
在这个扩展函数中,可以像其他成员函数一样用this。而且也可以像普通的成员函数一样,省略他。
package strings
fun String.lastChar(): Char = this.get(this.length - 1) //接收者对象成员可以不用this来访问在扩展函数中,可以直接访问被扩展的类的其他方法和属性,就好像是在这个类自己的方法中访问它们一样。注意,扩展函数并不允许你打破它的封装性。和在类内部定义的方法不同的是,扩展函数不能访问私有或者受保护的成员。
3.3.1 导入扩展函数
对于你定义的一个扩展函数,它不会自动的在整个项目范围类生效。相反,如果你要使用它,需要进行导入,就像其他任何的类或者函数一样。为了避免偶然性的命名冲突。Kotlin允许你和导入类一样的语法来导入单个函数:
import string.lastChar
val c = "Kotlin".lastChar()当然,用*来导入也是可以的:
import string *
val c = "Kotlin".lastChar()可以使用关键字as来修改导入的类或者函数名称:
import string.lastChar as last
val c = "Kotlin".last()当你在不同的包中,有一些重名的函数,在导入时给它的重新命名就显得很有必要了,这样可以在同一个文件中去使用它们。在这种情况下,对于一般的类和函数,还有另一个选择:可以选择用全命名来指出这个类或者函数。对于扩展函数,Kotlin的语法要求你用简短的名称,修改,在导入声明的时候,关键字as就是你解决命名冲突问题的唯一方式。
3.3.2 从Java中调用扩展函数
实质上,扩展函数是静态函数,它把调用对象作为它的第一参数。调用扩展函数,不会扩展适配的或者任何运行时的额外消耗。
这使得从Java中调用Kotlin的扩展函数变的非常简单:调用这个静态函数,然后把接收者对象作为第一个参数传进去集合。和其他顶层函数一样,包括这个函数的Java类的名称,是由这个函数声明的文件名称决定的。假设它声明在一个叫StringUtil.kt文件中:
/* Java */
char c = StringUtil.lastChar("Java")这个扩展函数被声明为顶层函数,所以,它将会被编译为一个静态函数。在Java中静态导入lastChar函数,就可以直接使用它,如lastChar(“Java”)。
3.3.3 作为扩展函数的工具函数
现在,可以写一个joinToString函数的终极版本了,它和你在Kotlin标准库中看到的一摸一样。
/*扩展函数joinTOString()*/
fun <T> Collection<T>.joinToString( //为Collection<T>声明一个扩展函数
separator: String = ",", //默认参数
prefix: String = "",
postfix: String = ""
): String {
val result = StringBuilder(prefix)
for ((index, element) in this.withIndex()) { //this指向接收者对象:T的集合
if (index > 0) result.append(separator)
result.append(element)
}
result.append(postfix)
return result.toString()
}
>>> val list = listOf(1,2,3)
>>> println(list.joinToString(separator = ";",
prefix = "(",postfix = ")"))

可以给元素的集合类添加一个扩展函数,然后给所有的参数添加一个默认值。这样,你就可以像使用一个类的成员函数一样,去调用joinToString了:
>>> val list = arrayListOf(1,2,3)
>>> println(list.joinToString(""))
因为扩展函数无非就是静态函数的一个高效的语法糖,可以使用更具体的类型来作为接收者类型,而不是一个类。假设你需要一个join函数,只能由字符串集合来触发。
fun Collection<String>.join(
separator: String=",",
prefix: String="",
postfix: String=""
)=joinToString(separator,prefix,postfix)
>>> println(listOf("one","two","eight").join(" "))
如果使用其他类型的对象列表来调用,将会报错:
>>> listOf(1,2,8).join()
Error:Type mismatch:inferred type is List<Int> but Collection<String> was expected扩展函数的静态属性也决定了扩展函数不能被之类重写。
3.3.4 不可重写的扩展函数
在Kotlin中,重写成员函数是很平常的一件事。但是,不能重写扩展函数。假设这里有两个类,View和它的子类Button,然后Button重写了父类的clike函数。
/*重新成员函数*/
open class View{
open fun click()=println("View clicked")
}
class Button:View(){
override fun click() {
println("Button clicked") //Button 继承View
}
}当你声明了类型View的变量,那么它被赋值为Button类型的对象,因为Button是View的子类。当你在调用这个变量的一般函数,比如clicke的时候,如果这个函数被Button重写了,调用子类被重写的函数 那么这里
将会调用到Button中重写的函数:
fun main() {
val view:View= Button()
view.click() //具体调用那个方法,由实际的view的值来决定
}
但是对于扩展函数来说,并不是这样的。如下:
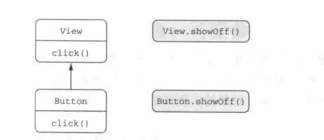
扩展函数并不是类的一部分,它是声明在类之外的。尽管可以给基类和子类都分别定义一个同名的扩展函数,当这个函数被调用时,它会用到哪一个呢?这里,它是由该变量的静态类型所决定的,而不是这个变量的运行时类型。
下面的例子就展示了两个分别声明在View和Button的showOff扩展函数。
fun main() {
val view= Button()
view.showOf()//扩展函数被静态的解析
}
/*不能重写扩展函数*/
fun View.showOf()= println("I'm a view")
fun Button.showOf()= println("I'm a button!")
当你在调用一个类型为View的变量的showOff函数时,对应的扩展函数会被调用,尽管实际上这个变量现在是一个Button的对象。
回想一下,扩展函数将会在Java中被编译为静态函数,同时接收值将会作为第一个参数,对于此你应该清楚,因为Java会执行相同的函数:
/* Java */
>>> View view = new Button();
>>> ExtensionKt.showOf(view);//showOff函数声明在extension.kt中
I'm a view如你所见,扩展函数并不存在重写,因为Kotlin会把它们当作静态函数对待。
注意:
如果一个类的成员函数和扩展函数有相同的签明,成员函数往往会被优先使用。你应该牢记,当在扩展API的时候;如果添加一个和扩展函数同名的成员函数,那么对应类定义的消费者将会重新编译代码,这将会改变它的意义并开始指向新的成员函数。
3.3.5 扩展函数
扩展函数提供了一种方法,用来扩展API,可以用来访问属性,用的是属性的语法而不是函数的语法。尽管它们被称为属性,但它们可以没有任何状态,因为没有合适的地方来存储它,不可能给现有的Java对象的实例添加额外的字段。但有时短语法仍然是便于使用的。
上节,我们又定义了一个lastChar的函数,现在让我们把它转换成一个属性试试。声明扩展属性
/* 声明一个扩展函数 */
val String.lastChar: Char
get() = get(length - 1)可以看到,和扩展函数一样,扩展属性也像接收者的一个普通的成员属性一样。这里,必须定义getter函数,因为没有支持字段,因此没有默认getter的实现。同理,初始化也不可以:因为没有地方存储初始化值。
如果在StringBuilder上定义一个相同的属性,可以置为var,因为StringBuilder的内容是可变的。声明扩展属性
/* 声明一个可变的扩展函数 */
var StringBuilder.lastChar: Char
get() = get(length - 1)
set(value: Char) {
this.setCharAt(length - 1, value)
}可以像访问使用成员属性一个访问它:
fun main() {
println("Kotlin".lastChar())
val sb = StringBuilder("Kotlin?")
sb.lastChar = '!'
println(sb)
}
注意,当你需要从Java中访问属性的时候,应该显式地调用它的getter属性:StringUtilKt.getLastChar(“Java”)。
3.4 处理集合:可变参数、中辍调用和库的支持
这一节将会展示Kotlin标准库中用来处理集合的一些方法。另外,也会设计几个相关的语言特性:
- 可变参数的关键vararg,可以用来声明一个函数将可能有任意数量的参数
- 一个中辍表示法,当你在调用一些只有一个参数的函数时,使用它会让代码更简练
- 解构声明,用来把一个单独的组合值展开到多个变量中
3.4.1扩展Java集合的API
我们开始本章的前提,是基于Kotlin中的集合与Java的类的相同,但对API做了扩展。我们看一个示例,用来获取列表中最后一个元素并找到数字集合中的最大值:
fun main() {
val strings: List<String> = listOf("first", "second", "fourteenth")
println(strings.last())
val numbers: Collection<Int> = setOf(1, 14, 2)
println(numbers.max())
}
我们感兴趣的是它是怎么工作的:尽管它们是Java库类的实例,为什么在Kotlin中能对集合有这么多丰富的操作?现在答案很明显了:因为函数last和max都被声明成了扩展函数。
last函数不会比String的lastChar更复杂,在上节讨论过:它(last)是List类的一个扩展函数。对于max,我们做一个简单的声明(真正的库函数不仅用于Int数字,而且适用于任何可比较的元素):
fun <T> List<T>.list(): T {/* 返回最后一个元素 */
}
fun Collection<Int>.max(): Int {/* 找到集合的最大值 */
}许多扩展函数在Kotlin标准库中都有声明,在这里,我们不会列出所有这些方法。你可能会想知道,在Kotlin标准库中学习所有内容的最佳方法。这个并没有比较,在你需要操作集合或任何其他对象的时候,IDE中的代码补全功能,将为你列出所有可能用于该类型对象的方法,不管是普通函数或者扩展函数,都会有显式,你可以选择所需的方法。除此之外,标准库的引用会列出库中每个类的所有可用的函数,包括成员函数及扩展函数。
4 类、对象和接口
4.1 定义类继承结构
4.1.1 Kotlin 中的接口
声明接口
interface Clickable{
fun click()
}实现接口
class Button : Clickble {
override fun click() {
println("I was clicked")
}
}

Kotlin实现接口与 Java 有那些不同
Kotlin 在类后面使用冒号来代替 Java 中的 extends 和 implements 关键词。 和 Java 一样,一个类可以实现任意多个接口,但只能继承一个类型。
override 修饰符的作用
- 相同
与 Java 中的 @Override 注解类似,override 修饰符用来标注被重写的父类或者接口的方法和属性。
- 不同
在 Kotlin 中使用 override 修饰符是强制要求的。这会避免先写出实现方法再添加抽象方法造成的意外重写:你的代码将不能编译,除非你显式地将这个方法标注为 Override 或者重命名它。
如何给接口添加一个默认实现的方法
接口的方法可以有一个默认实现的方法。
interface Clickable{
fun click() // 普通的方法声明
fun showOff() = println("I'm clickable!") // 带默认实现的方法
}实现一个带有默认实现的方法的接口要注意什么
如果你实现了这个接口,你需要为 click 提供一个实现。可以重新定义 showOff() 方法的行为,或者如果你对默认行为感到满意也可以直接省略它。(默认实现的方法也可以被重写)
定义实现了同样方法的接口
interface Focusable {
fun setFocus(b: Boolean) = println("I ${if (b) "got" else "lost"} focus.")
fun showOff() = println("I'm focusable!")
}在类中实现两个有相同默认实现方法的接口会发生什么
在这两个接口中都带有默认实现的 showOff() 方法:在没有显示的实现 showOff() ,会得到编译错误信息。
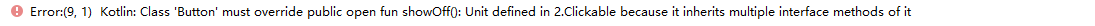
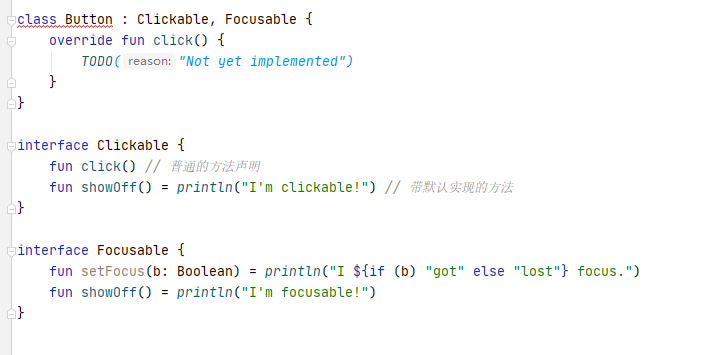
解决办法
必须显式的实现相同方法。
调用继承(接口)的默认实现方法
class Button : Clickable, Focusable {
override fun click() {
TODO("Not yet implemented")
}
//如果同样的继承成员不止一个实现,必须提供一个显示的实现。
override fun showOff() {
// 使用尖括号加上父类名字的“super”表明了你想要调用哪一个父类的方法
super<Clickable>.showOff()
super<Focusable>.showOff()
}
}通过调用继承的两个父类型中的实现来实现 showOff() 。

4.1.2 open、final 和 abstract 修饰符:默认为 final
kotlin 中如何继承一个类
如果你想要创建一个类的子类,需要使用 open 修饰符来标示这个类。此外需要给每个可以被重写的属性或者方法添加 open 属性。
声明一个带open 方法的 open 类
open class RichButton : Clickable {
fun disable() {} // 这个函数是 final 的: 不能在子类中重写它。
open fun animate() {} // 这个函数是 open 的: 可以在子类中重写它
// 这个函数重写了 open 函数并且它本身同样是 open 的
override fun click() {
TODO("Not yet implemented")
}
}默认 final 的好处
类默认 final 带来了一个重要的好处就是这使得在大量的场景中的只能转换成为可能。
智能转换的前提
智能转换只能在进行类型检查后没有改变过的变量上起的作用。对于一个类来说,这意味着智能转换在val类型并且没有自定义访问器的类属性上使用。 这个前提意味着属性必须是 final 的,否则如果一个子类可以重写属性并且定义一个自定义的访问器将会打破智能转换的关键前提。
抽象类的默认修饰符
抽象成员始终是open的,所以不需要显式地使用open修饰符。
声明一个抽象类
abstract class Animated {
abstract fun animate() // 这个函数是抽象的:它没有实现必须被子类重写
// 抽象类中的非抽象函数 并不是默认 open 的,但是可以标注为 open的
open fun stopAnimating() {
}
fun animateTwice() {}
}4.1.4 内部类和嵌套类:默认嵌套类
内部类:非静态嵌套类,也被成为内部类。
嵌套类:静态嵌套类,嵌套类多称为:静态嵌套类。
Kotlin中嵌套类和Java中的不同
在Kotlin中的嵌套类不能访问外部类的实例,除非你特别的做出要求。
在序列化时使用内部类
在你定义一个 View 元素,它的状态时可序列化的。想要序列化一个视图可能并不容易,但是可以把所有需要的数据复制到另一个辅助类中去。
interface State : Serializable
interface View {
fun getCurrentState(): State
fun restoreState(state: State) {}
}声明State接口去实现Serializable。View接口声明了可以用来保存视图状态的getCurrentState和restoreState方法。
用内部类的java代码来实现View
public class Button implements View{
@Override
public State getCurrentState(){
return new ButtonState();
}
@Override
public voiew restoreState(State state){
/**/
}
public class ButtonState implements State{
/**/
}
}问题:在运行时你会得到 java.io.NotSerializable.Exception:Button 异常,在你序列化声明的按钮状态时。这个可能看起来会很奇怪:你序列化的变量是ButtonState类型,为什么会有Button异常呢?
无法序列化的原因
在java中,当你在另一个类中声明一个类时,它会默认变成内部类。案例中:ButtonState类隐示的存储了它的外部Button类的应用。从而解释了为什么ButtonState不能被序列化。
修复无法序列化
需要声明ButtonState类是static的。将嵌套类声明为static会冲这个类中删除包围它的类的隐式引用。
在kotlin中使用嵌套类来实现 View
class Button : View {
override fun getCurrentState(): State {
TODO("Not yet implemented")
}
override fun restoreState(state: State) {
TODO("Not yet implemented")
}
// 这个类与Java中的静态潜逃类类似
class ButtonState : State {
}
}kotlin中默认行为是嵌套类。
如何让默认嵌套类的类型变为内部类!
要把它(嵌套类)变成为一个内部类来持有一个外部类的引用的话需要使用 inner 修饰符。
kotlin中内部类访问外部类
在kotlin中引用外部类实例的语法与java不同。需要使用this@Outer从Inner类去访问Outer类。
创建内部类
fun main() { var innerClass = InnerClass() innerClass.testClass().innerFun() } class InnerClass { // 创建一个变量用来让内部类的方法调用 val tag = "外部变量" // 使用inner修饰符修饰类如果不修饰内部类无法调用到外部变量 inner class testClass { fun innerFun() { println("内部类调用外部变量:$tag") } } }
内部类调用到外部变量需要声明到inner修饰符,当然外部类调用内部类不需要。

4.1.5 密封类:定义受限的类继承结构
什么是密封类”sealed“
sealed 类。为父类添加了一个新的 sealed 修饰符,可对创建的子类做出严格的限制。所有的子类必须嵌套在父类中。
为什么要使用密封类(定义受限的类继承结构)
作为接口实现的表达式 👇
interface Expr
class Num(val value: Int) : Expr
class Sum(val left: Expr, val right: Expr):Expr
fun eval(e: Expr): Int =
when (e) {
is Num -> e.value
is Sum -> eval(e.left) + eval(e.right)
else -> // 必须检查 else 分支
throw IllegalArgumentException("Unknown expression!")
}
当使用 when 结构来执行表达式的时候,Kotlin 编译器会强制检查默认选项。在这个例子中,不能返回一个有意义的值,所以直接返回异常状态。
更重要的是,如果你添加了一个新的子类,编译器并不能发现你修改了。如果你忘记添加一个新的分支,就会选择默认选项,这又可能导致潜在的 bug。
如何使用密封类 “sealed”
sealed class Expr { //将基类标记为封闭的
class Num(val value: Int) : Expr()
class Sum(val left: Expr, val right: Expr) : Expr() // 将所有可能的类作为嵌套类列出
}
fun eval(expr: Expr): Int =
// “when”表达式覆盖了所有的可能情况,所以不再需要 else 分支
when (expr) {
is Expr.Num -> expr.value
is Expr.Sum -> eval(expr.left) + eval(expr.right)
}如果你在 when 表达式中处理了所有的 sealed 类的子类,你就不再需要提供默认分支。注意,sealed 修饰符隐含的这个类是一个 open 类,你不再需要显式地添加 open 修饰符。
4.2 声明一个带默认构造方法或属性的类
kotlin中构造方法和java中有那些不同
与java中一个类可以声明一个或多个构造方法。kotlin也是类似的,只是做出了一些修改:区分了主构造方法(通常是主要而简洁的初始化类的方法,并且在类体外部声明)和从构造方法。
4.2.1 初始化类:主构造方法和初始化代码块
什么是主构造方法。
class User(val nickname:String)这段被括号围起来的代码块就叫做主构造方法。它有两个目的:表明构造方法的参数,以及定义使用这个参数的属性。
明确的主构造方法声明
class User constructor(_nickname: String) { // 带一个参数的主构造方法
val nickname: String
init { // 初始化代码块
nickname = _nickname
}
}现在来看看完成同样功能的代码具体是什么样子。
两个关键词 construtor 和 init。 constructor 关键词用来开始一个构造方法或者从构造方法的声明。init 关键词用来引入初始化代码块。这种代码块包含了类在创建时执行的代码,并且会和主构造方法一起使用。因为主构造方法有语法限制,不能包含初始化代码,这就是需要初始化代码块(init)的原因。同时可以创建多个初始化代码块。
用参数来初始化属性
class User(_nickname: String) { // 带一个参数的构造方法
val nickname: String = _nickname // 用参数来初始化属性
}在例子中,不需要把初始化代码放在初始化代码块中,因为它可以与nickname属性声明结合。如果主构造方法没有注解或可见性修饰符,同样可以去除 constructor 关键词。
用最简洁的方法再次初始化类
class User(val nickname:String) // “val” 意味相对应的属性会用构造方法的参数来初始化。前几个案例用 val 关键词声明了属性。如果属性用相对应的构造方法参数来初始化,代码可以通过把 val 关键词加载参数前的方法来简化它。可以用来代替类中的属性定义了。
为构造方法提供默认值
class User(val nickname: String, val isSubscribed: Boolean = true) // 为构造方法提供一个默认值 可以像函数参数一样为构造方法声明默认值。
如何让一个类不被其他代码实例化
如果想要你的类不被其他代码实例化,必须把构造方法标记为 private。
class Secretive private constructor() // 这个类有 private 构造方法4.2.2 构造方法:用不同的方法来初始化方法
为什么要使用多种方法初始化父类
最常见的一种就是当你需要扩展一个框架类来提供多个构造方法,以便于通过不同的方法来初始化类的时候。
父类使用从构造方法
open class View {
constructor(ctx: Context) { // 从构造方法
//some code
}
constructor(ctx: Context, attr: AttributeSet) { // 从构造方法
//some code
}
}扩展父类
class MyButton : View {
constructor(ctx: Context) : super(ctx) {
// 调用父类构造方法
}
constructor(ctx: Context, attr: AttributeSet) : super(ctx, attr) {
}
}调用父类的另一个构造方法
class MyButton : View {
constructor(ctx: Context) : this(ctx, My_SYTLE) {
// 委托给这个类的另一个构造方法
}
constructor(ctx: Context, attr: AttributeSet) : super(ctx, attr) {
}
}从构造方法中调用你自己类的另一个构造方法。
可以修改 MyButton类 使得一个构造方法委托给同一个类的另一个构造方法,为参数传入默认值,图下👇。第二个方法继续调用super()。

注意 如果主构造函数中存在参数那么次构造函数中使用需要继承它。
class User(name:String){ constructor(name:String,age:Int):this(name) //name需要继承 }
4.2.3 实现在接口中声明的属性
在接口中声明一个属性
interface User {
val nickname: String
}接口可以包含抽象属性声明。
这意味这实现User接口的类需要提供一个取得nickname值的方式。
实现接口中的属性 三种
第一种
// 主构造方法属性
class PrivateUser(override val nickname: String) : User {
}对于 PrivateUser 来说,你是用了间接的语法直接在主构造方法中声明了一个属性。这个属性实现了来自于User的抽象属性,所以你将其标记为 override。


运行结果
第二种
class SubscribingUser(val email: String) : User {
override val nickname: String get() = email.substringBefore('@') // 自定义getter
}对于 SubscribeingUser 来说,nikename属性通过一个自定义 getter 实现。这个属性没有一个支持字段来存储它的值,它只有一个 getter 在每次调用时从 email 中得到昵称。


运行结果
第三种
class FacebookUser(val accoundId: Int) : User {
override val nickname = getFacebookName(accoundId) // 属性初始化
fun getFacebookName(text: String): String {
return text
}
}nickname在SubscribingUser和FackbookUser中的不同实现。即使它们看起来很相似,第一个属性有一个自定义getter在每次访问时计算 subscringBefore,然后 FackbookUser中的属性有一个支持字段来存储在类初始化时计算得到数据。


运行结果
4.2.4 通过 getter或setter访问支持字段
关于两种属性的例子:存储值的属性和具有自定义访问器在每次访问时的属性。现在让我们来看看怎么结合这两种来实现一个既可以存储值又可以被值访问和修改时提供额外逻辑的属性。要支持这种情况,需要能够从属性的访问器中访问它的支持字段。
假设在任何适合对存储的属性中的数据进行修改时输出日志,你声明了一个可变属性并且在每次 setter 访问时执行额外的代码。
/* 在 setter 中访问支持字段 */
class User(val name:String) {
var address: String = "unspecified"
set(value: String){
println("""
Address was changed for $name:"$field" -> "$value".""".trimIndent()) //读取支持字段的值
field = value // 更新支持字段的值
}
}>>> val user = User("Alice")
>>> user.address = "Elasenheimerstrasse 47, 80687 Muenchen"
Address was changed for Alice:
"unspecified" -> "Elsenheimerstrasse 47, 80687 Muenchen"可以像平常一样通过使用 user.address = “new value” 来修改一个属性的值,这其实在底层调用了setter。在这个例子中,setter 被重新定义了,所以额外的输出日志的代码被执行了(简单起见,这里直接将其打印出来)。
在 setter 的函数体中,使用了特殊的标识符 field来访问支持字段的值。在 getter 中,只能读取值:而在 setter 中,既能读取它也能修改它。
4.3 编译器生成的方法:数据类和委托
4.3.2 数据类:自动生成通用方法的实现.
实现一个数据类需要重写方法:toString、equals和hashcode。
数据类
data class Client(val name:String,val postalCode:Int)这是一个数据类,重写了所有标准的Java方法:
- equals 用来比较实例
- hashCode用来作为例如HashMap这种基于哈希容器的键
- toString用来为类生成按声明顺序排列的所有字段的字符串表达形式
- copy函数,可以用这个函数复制并修改部分属性。
创建数据类
并且使用copy函数复制修改
fun main() { val li=Student("小李",15) val li18=li.copy(age = 18) println(li) println(li18) } data class Student(val name:String,val age:Int)

4.4 “object” 关键字: 将声明一个类与创建一个实例结合起来
这个关键词定义一个类并同时创建一个实例(换句话说就是一个对象)。
- 对象声明是定义一个单例的一种方式。
- 伴生对象可以持有工场方法和其他与这个类的相关,但是在调用时并不依赖类实例方法。它们的成员可以通过类名来访问。
- 对象表达式用来代替Java的匿名内部类
对象表达式
假如一个方法需要一个类,那么Kotlin将对象表达式传递给它就可以了
方法接收一个类(object:匿名对象的类型{ override fun 匿名类的方法(){ println("通过对象表达式调用了匿名类") } })这个方法参数需要匿名类通过对象表达式重写了类的方法。
4.4.1 对象声明:创建单例易如反掌
为什么使用对象声明?
在面向对象系统中一个相当常见的情形就是只需要一个实例的类。例如,可以使用一个对象声明来表示一个组织的工资单。
在Java中是如何实现单例模式?
定义一个使用private构造方法并且用静态字段来持有这个类仅有的实例。
什么是对象声明
Kotlin通过使用对象声明功能为这一切提供了最高级的语言支持。对象声明将类声明与该类的单一实例声明结合到了一起。
对象声明使用
object Payroll {
val allEmployees = arrayListOf<Person>()
fun calculateSalary() {
for (person in allEmployees){
}
}
}对象声明通过 object 关键词引入。与类一样,一个对象声明也可以包含属性、方法、初始化语句块等的声明,唯一不允许的是构造方法。对象声明在定义时就创建了构造对象,不需要在代码的其他地方调用构造方法。对象声明同样可以继承类和接口。
5 Lambda 编程
5.1 Lambda表达式和成员引用
5.1.1 Lambda 简介:作为函数参数的代码块
在代码中存储和传递一小段行为是常有的任务。例如,“当一个事件发生的时候运行这个事件处理器”又或是“把这个操作应用到这个数据结构的所有元素上”。在老版本的Java中可以使用匿名函数。
使用函数式编程 提供了另外一种解决问题的方法:
把函数当作值来对待。可以直接传递函数,而不需要先声明一个类再传递一个类的实例。使用 lambda 表达式后代码会变的更加简洁。
例子。假设你要定义一个点击按钮的行为,添加一个处理点击的监听器。监听器实现了想对应的接口 OnClickListener 和它的一个方法 onClick。
/* 用匿名内部类实现监听器 */
button.setOnClickListener(new OnClickListener(){
@Override
public void onClick(View view){
/*点击之后执行的动作*/
}
})使用匿名内部类的写法,更加冗余。接下来使用 lambda 写法
/* 用 lambda 实现监听器 */
button.setOnClickListener{ /* 点击后执行操作 */ }5.1.2 Lamda 和 集合
良好的编程风格原则之一是避免代码的重复。我们对集合执行大部分任务都遵循这几个通用的模式,所以要实现这几个模式的代码应该放在一个库里。在没有 lambda 的帮助,很难为集合提供一个好用方便的库。
看个例子。
创建一个 Person 类,它包含了这个了的名字和年龄信息。
data class Person(val name:String, val age :Int)假设你现在要在列表中找到年龄最大的那个人。
/* 手动在集合中搜索 */
fun findTheOldest(people:List<Person>){
var maxAge = 0 //存储最大年龄
var theOldest:Person ?= null //存储年龄最大的人
for (person in people){
if(person.age > maxAge){ //如果下一个比现在年龄最大的人还要大,改变最大值
maxAge = person.age
theOldest = person
}
}
println(theOldest)
}
>>> val people = listOf(Person("Alice",29),Person("Bob",31))
>>> findTheOldest(people)
Person(name = Bob,age = 31)/* 用 lambda 在集合中搜索 */
>>> val people = listOf(Person("Alice",29),Person("Bob",31))
>>> println(people.maxBy{it.age}) // 比较年龄最大的元素
Person(name = Bob, age = 31)maxBy函数可以在任何集合上调用,且只需要一个参数:函数指定比较哪个值来找到最大元素。
花括号中的代码 {it.age}就是实现了这个逻辑的lmabda。 它接收一个集合中的元素作为实参(作用 it 引用它)并且返回用来比较的值。在这个例子中,集合元素是Person对象,用来比较的是存储在其age属性中的年龄。
/* 用成员引用 */
people.maxBy(Person:age)5.1.3 Lambda 表达式的语法
概述 lambda
一个 lambda 把一小段行为进行编码,你能把它当作值到处传递。它可以被独立地声明并储存一个变量。
/* lambda 表达式的语法 */
{x:Int,y:Int -> x+y}
/* 参数 -> 函数体 */Kotlin 的lambda 表达式始终用花括号包围。实参并没有用括号括起来。箭头把实参列表和lambda 函数体隔开了。
可以把 lambda表达式存储在一个变量中,把这个变量当作普通函数对待(即通过相应实参调用它)
>>> val sum = {x:Int,y:int -> x+y}
>>> println(sum(1,2)) // 调用保存在变量中的lambda
3Kotlin 中的语法约定,如果 lambda 表达式是函数调用的最后一个实参,它可以放到括号外边。在这个例子中lambda是唯一的实参,所以可以放到括号外边
people.maxBy(){p:Person -> p.age}当 lamdba 是函数的唯一实参时,还可以去除调用代码中的空括号。
people.maxBy{p:Person -> p.age}三种语法形式的含义都是一样的,但最后都是易读的。如果lambda是唯一的实参,你当然愿意在写代码的时候省掉这个括号。而当你有多个实参时,既可以把lambda留在括号内来强调它是一个实参,也可以把它放在括号外面,两种选择都是可行的。如果你想传递两个或多个lamdba,不能把超过一个的lamdba放在外面。这时使用常规语法来传递它们通常是更好的选择。
回顾 joinToString 函数 (对元素添加分隔符)。 Kotlin 标准库中也有定义它,标准库中的这个版本的不同之处在于它可以接收一个附加的函数参数。这个函数可以使用 toString函数以外的方法把一个元素转换成字符串。
打印出人的名字
/* 把 lambda 作为命名实参传递 */
>>>val people = listOf(Person("Alice",31),Person("Bob",29))
>>>val names = people.joinToString(separator = "",transform = {p:Person -> p.name})
>>>println(names)
Alices Bob用更简单的方法
/* 把 lambda 放在括号外传递 */
people.joinToString(" "){p:Person -> p.name}简化语法,移除参数类型
/* 省略 lambda 参数类型 */
people.maxBy{p:Person -> p.age} // 显式地写出参数类型
people.maxBY{p->p.age} // 推导出参数类型和局部变量一样,如果 lambda 参数的类型可以被推导出来,你就不需要显式地指定它。以这里的 maxBy 为例子,其参数类型始终和集合的元素类型相同。编译器知道你是对一个Person对象的集合调用maxBy函数,所以它能推断出 lambda参数也会是Person类型。也存在不能推断出的情况,先遵循:先不声明类型,等编译器报错后再指定它。
最后的简化是使用默认参数名称 it 代替命名参数
/* 使用默认参数名称 */
people.maxBy(it.age) //"it"是自动生成的参数名称仅在参数名称没有显式地指定时这个默认的名称才会生成。
可以用变量存储 lambda 表达式
>>> val getAge = {p:Person -> p.age}
>>> people.maxBy(getAge)lambda 并没有被限制在这样小的规模,它可以包含更多的语句。
>>> val sum = {x:Int,y:Int ->
println("Computing the sum of $x and $y...")
x + y}
>>> println(sum(1,2))
Computing the sum of 1 and 2...
35.1.4 在作用域中访问变量
在声明一个匿名内部类的时候,能够在这个匿名类内部引用这个函数的参数和局部变量。
而在使用 lambda 声明的时候,也可以做同样的事情。如果在函数内部使用 lambda 也可以访问这个函数的参数,还有在 lambda 之前定义的局部变量。
forEach 函数
用 forEach 函数展示 上述行为。便利字符串操作。
它是最基本集合操作函数之一;它所作的全部事情就是在集合中的每个元素上都调用给定的 lambda。forEach 函数比普通for 函数循环更简洁,除此之外没有其它优势,所以并不急于把所有的循环更改为 lambda。
/* 在 lambda 中使用函数参数 */
fun printMessageWithPrefix(message : Collection<String>,prefix:String){
messages.forEach{ // 接受 lambda 作为实参指定对每个元素操作
println("$prefix $it") // 在 lambda 中访问 “prefix”
}
}
>>> val errors = listOf("433 Forbidden","404 Not Found")
>>> printMessagesWithPrefix(errors,"Error:")
Error:403 Forbidden
Error:404 Not FoundKotlin 和 Java的一个显著区别就是,在 Kotlin 中不会仅限于访问 final 变量,在 lambda 内部也可以修改变量。
/* 在lambda中改变局部变量 */
fun printProblemCounts(responeses:Collection<String>){
var clientErrors = 0
var serverErrors = 0
responeses.forEach{
if(it.startsWith("4")){
clientErrors ++
}else if(it.startsWith("5")){
serverErrors++
}
}
println("$clientErrors client error,$serverErrors server errors")
}
>>> val responses = listOf("200 OK","418 I'm a teapot","500 Internal Server Error")
...
>>> printProblemCounts(responses)
1 client errors,1 server errors于 Java 不同,Kotlin 允许在 lambda 内部访问非 final 变量甚至修改它们。从 lambda 内访问外部变量,我们称这个变量被 lambda捕捉,如同上述的案例中的 prefix,clientErrors,serverErrors一样。
默认情况下,局部变量的声明期被限制在声明这个变量的函数中。但是如果它被lambda捕捉了,使用这个变量的代码可以被存储并稍后执行。
如果 lambda 被用作 事件处理器 或者用在其他 异步执行 的情况下,对局部变量的修改只会在 lambda 执行的时候发生。
反面案例
fun tryToCountButtonClicks(button:Button):Int{ var clicks = 0 button.onClick{clicks++} return clicks }这个函数始终返回0。尽管 onClick 处理器可以修改clicks的值,你并不能观察到值发生了变化,因为onClick处理器是在函数返回之后调用的。这个函数正确的实现方法需要把点击次数存储在函数外依然可以访问到的地方–例如类的属性,而不是存储在函数的局部变量中。
5.1.5 成员引用
如果把函数转换成一个值,你就可以传递它。
val getAge = Person::age //引用 age这种表达式称为 成员引用,它提供了简明语法,来创建一个调用单个方法或者访问单个属性的函数值。 双冒号把类名称与你要引用的成员(一个方法或者一个属性)名称隔开
Person::age //类::成员
等价于
val getAge = {person:Person ->person.age}注意,不管你引用的是函数还是属性,都不要在成员引用的名称后面添加括号。
成员引用和调用该函数的lambda具有一样的类型,所以可以互换使用:
people.maxBy(Person::age)还可以引用顶层函数
fun salute() = println("Salute!") >>> run(::salute) // 引用顶层函数 Salute!这种情况下,你省略了类名称,直接以::开头。成员引用::salute被当作实参传递给库函数run,它会调用想对应的函数。
如果 lambda 要委托给一个接收多个参数的函数,提供成员引用代替它将会非常方便
val action = {person:Person,message:String -> sendEmail(person,massage) //这个lambda委托sendEmail函数 } val nextAction = :: sendEmail //用成员引用代替/* 用构造方法引用存储或者延期执行创建类实例的动作。 构造方法引用的形式在双冒号后指定类的名称: */ data class Person(val name:String,val age:Int) >>> val createPerson = ::Person //创建Person实例的动作被保存成了值 >>> val p = createPerson("Alice",29) >>> println(p) Person(name = Alice,age = 29)可以用同样的方法引用扩展函数
fun Person.isAdult() = age >= 21 val predicate = Person::isAdult尽管 isAdult 不同类的成员,还是可以通过引用访问它,这个访问的成员没有两样:person.isAdult()。
绑定引用
在 kotlin 1.0 中 ,当接受一个类的方法或者属性引用时,你始终需要提供一个该类的实例来调用这个引用。Kotlin1.1计划支持绑定成员引用,它允许你使用成员引用语法捕捉特定实例对象的方法引用。
>>> val p = Person("Dmitry",34) >>> val personAgeFunction = Person::age >>> println(personsAgeFunction(p)) 34 >>> val dmitrysAgeFunction = p::age >>> println(dmitryAgeFunction()) 34注意,personsAgeFunction是一个当参数函数(返回给定了的年龄),而dmitryAgeFunction是一个零参数的函数(返回已经指定好的人的年龄)。
在 Kotlin1.1之前,你需要显式地写出 lambda{p.age},而不是使用绑定成员引用p::age。
5.2 集合的函数式API
我们先从filter和map这类函数及它们背后的概念开始。
5.2.1 基础:filter和map
filter和map函数形成了集合操作的基础,很多集合操作都是借助它们来表达的。
通过两种样子的例子帮助你来理解,一个纯数字形式一个使用自定义的Person类来实现。
data class Person(val name:String,val age:Int)filter函数
遍历集合并选出引用给定 lambda 条件 后会返回true的那些元素
>>> val list = listOf(1,2,3,4) >>> println(list.filter{it%2==0}) [2,4]
map函数
对集合中每个元素应用给定的函数并把结果收集到一个新的集合中。
根据lambda参数作为判断生成新的集合。
>>> val list = listOf(1,2,3,4) >>> println(list.map{it*it}) [1,4,9,16]
如果直想打印名字列表,而不是完整信息,可以用map变换列表:
>>> val people=listOf(Person("Alice",29),Person("Bob",31)) >>> println(people.map{it.name}) [Alice,Bob]使用 成员引用 同样可以
people.map(Person::name)
当需要获得分组中最大人的名字时。
val maxAge = people.maxBy(Person::age).age people.filter{it.age == maxAge}map 应用过滤和变换函数
>>> val numbers = mapOf(0 to "zero",1 to "one") >>> println(numbers.mapValues{it.value.toUppterCase()}) // 对map集合的值进行操作 [0=ZERO,1=ONE]键和值分别由各自的函数来处理。filterKeys和mapKeys过滤和变换map的键,而另外的filterValues和mapValues过滤和变换对应的值。
5.2.2 “all”“any”“count”和“find”:对集合引用判断式
这些方法作用
Kotlin中,它们是通过 all 和 any 函数表达式的(检查集合中的所有元素是否都符合某个条件)。count 函数检查由多少元素满足判断式,而find函数返回第一个符合条件的元素。
案例:
检查一个人是否还没有到28岁。
val canBeInClub27 = {p:Person -> p.age <=27}如果是所有元素都满足判断式条件的应该使用 all 函数。()
>>> val people = listOf(Person("Alice",27),Person("Bob",31)) >>> println(people.all(canBeInClub27)) false如果你检查集合中至少存在一个匹配的元素,则使用 any 函数
>>> println(people.any(canBeInClub27))true
如果你想知道有多少元素满足判断式,使用count:
>>> val people = listOf(Person("Alice",27),Person("Bob",31)) >>> println(people.count(canBeInClub27)) 1
使用正确的函数完成工作:”count” VS. “size”
count 方法容易被遗忘,然后通过过滤集合之后再取大小来实现它:
>>> println(people.filter(canBeInClub27).size)
1再这种情况下,一个集合中间会被创建并用来存储所有满足判断式的元素。
而另一方面,count 方法只是最终匹配元素的数量,不关心元素本身,所以更高效。
要找到一个满足判断式的元素,使用 find 函数
>>> val people = listOf(Person("Alice",27),Person("Bob",31)) >>> println(people.find(canBeInClub27)) Person[name = Alice,age = 27]存在多个能够匹配的元素就返回其中第一个元素:或者返回 null,如果没有一个元素能满足判断式。find还有一个同义方法 firstOrNull,可以使用这个方法更加清楚的表达你的意图。
5.2.3 groupBy:把列表转换成分组的map
当你想把人按照年龄分组,相同年龄的人放在一组。
groupBy: 按照表达式将几个进行分组并返回一个 map 集合
>>> val people = listOf(Perosn("Alice",31),Perosn("Bob",29),Person("Carol",31)) >>> println(people.groupBy{it.age})返回结果 map,是元素分组依据的键(这个例子中是age)和元素分组(persons)之间映射
{ 29 = [Person(name = Bob,age = 29)], 31 = [Person(name = Alice,age = 31), Person(name = Carol,age = 31)] }每个分组都是存储在一个列表中,结果的类型就是Map<Int,List
> 。可以使用像 mapKeys 和 mapValues 这也的函数对这个map做进一步的修改。
使用成员引用把字符串按照首字母分组:
>>> val list = listOf("a","ab",b) >>> println(list.groupBy(String::first)) {a = [a,ab], b = [b]}first并不是String类的成员,而是一个扩展。然而,可以把它当作成员引用访问。
5.2.4 flatMap 和 flatten:处理嵌套集合和元素
例子
假设你有一堆藏书,使用Book表示:
class Book(val title:String,val authors:List<String>)authors :保存书的所有作者。
统计出图书馆中所有作者的set;
books.flatMap{it.authros}.toSet() //包含撰写 “books” 集合中书籍的所有作者 setflatMap:作用,1.首先根据作为实参给定的函数对集合中的每个元素做转换(或者说映射),然后把多个列表合并(或者说平铺)成一个列表。
说明:
>>> val strings = listOf("abc","def") >>> pritnln(strings.flatMap{it.toList()}) [a,b,c,d,e,f]字符串上的toList函数把它转换成字符列表。
使用 map 函数,你会得到一个字符列表的列表。
flatMap 函数:执行后面操作,并返回一个包含所有元素(字符)的列表
回到例子中:
>>> val books = listOf(Book("Thursday Next",listOf("Jasper Fforde")), Book("Mort",listOf("Terry Pratchett")), Book("Good Omens",listOf("Terry Pratchett", "Neil Gaiman"))) >>> println(books.flatMap{it.authors}.toSet) [Jasper Fforde,Terry Pratchett,Neil Gaiman]book.authors 是存储了多个作者的集合。flatMap 函数把所有书籍的作者合并成变频的列表。
toSet调用移除了结果集合中的所有重复元素。
所以 Terry Pratchett 在输出中只出现了一次。
如果你只需要平铺一个集合,可以使用 flatten 函数:listOfLists.flatten
5.3 惰性集合操作:序列
你看到了关于许多链式调用的例子,例如 map 和 filter。这些函数会及早的创建中间集合,也就是说每一步的中间结果都被存储在一个临时列表。
people.map(Person::name).filter{it.startsWith("A")}Kotlin 标准库参考文档说明,filter 和 map 都会返回一个列表。这意味这上面的例子中的链式调用会创建两个列表:一个保存filter函数的结果,另一个保存 map函数的结果。如果源列表只有两个元素,这不是什么问题,但是如果有一百万个元素,(链式)调用就会变得十分低效。
为了提高效率可以将操作变换成序列,而不是使用集合:
people.asSequence() //把初始集合转换成序列 .map(Person::name) .filter{it.startsWith("A")} //系列支持和集合一样的API .toList() // 把结果序列转换会列表这个例子没有创建任何一个存储元素的,所以元素数量巨大的情况下性能显著提升。
Kotlin 惰性集合操作的入口就是 Sequence 接口。这个接口表示可以诸葛列举的元素序列。Sequence 只提供了一个方法,iterator,用来从序列中获取值
优势
Sequence接口的强大之处在于其操作的实现方式。序列中的元素求值是惰性的,因此可以使用序列更高效地对集合元素执行链式操作,而不需要创建额外的集合来保存过程中产生的总结结果。
为什么需要把序列转换回集合?把序列代替集合不是更方便吗?特别是它的这些优点。
大多数是这样的。如果你需要迭代序列中的元素,可以直接使用。而要使用其他API方法,例如下标访问元素,那么你需要将序列转换成列表。
通常,对一个大型集合执行链式操作时要使用序列。在后面的章节中继续讨论Kotlin常规集合的及早操作高效的原因,尽管它会创建中间集合。当集合拥有数量巨大的元素,元素为中间结果进行重新分配开销巨大,所以惰性求值是更好的选择。
5.3.1 执行序列操作:中间和末端操作
序列操作共分两种:
中间和末端。
一次中间操作返回的是另一个序列,这个序列知道如何变换原始序列中的元素。
而末端操作返回的是一个结果,这个结果可能是集合、元素、数字,或者其他的初始集合的变换序列中获得的任意对象。
sequence.map{...}.filter{...}//中间操作 .toList()//末端操作
没有末端操作的例子:
>>> listOf(1,2,3,4).asSequence() //序列化
... .map{print("map($it)");it*it} // 转换成map集合并操作它
... .filter{ print("filter($it)");it%2==0} //调用对象,然后根据条件过滤执行这段代码并不会在控制台上输出任何内容。这意味着map和filter变换被延期了,它们只有在获取结果的是否才会被应用(即末端操作被调用的时候):
>>>listOf(1,2,3,4).asSequence() ... .map{print("map($it);it*it")} ... .filter{print(filter("$it");it%2 == 0)} ... .toList() map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)末端操作触发执行了所有的延期计算。
计算执行的顺序。
一个笨办法实在每个元素上调用map函数,然后再结果序列的每个元素上再调用filter函数。
map和filter对集合就是这样做的,而序列不一样。对序列来说,所有操作是按序列应用再每个元素上:处理完第一个元素(先映射再过滤),然后完成第二个元素的处理,以此类推。
这种方法意味着部分元素根本不会发生任何转换
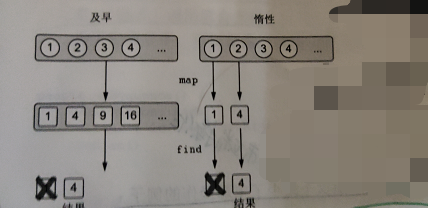
如果在轮到它们之前就已经取得了结果。我们来看一个map和find的例子。首先一个数字映射成它的平方,然后找到第一个比数字3大的条目:
>>> println(listOf(1,2,3,4).asSequence() .map{it*it} .find{it > 3} ) 4如果同样的操作被应用在集合而不是序列上时,那么 map 的结果首先被求出来。即变换初始集合中的所有元素。第二步,中间集合中满足判断式的一个元素会被找出来。而对于序列来说,惰性方法意味这你可以跳过处理部分元素。图 5.8 阐明了 这段代码两种求值方法之间的区别,一种是及早求值(使用集合),一种是惰性求值(使用序列)。
在集合上执行操作的顺序也会影响性能。
假设你有一个人的集合,想要打印集合中那些长度小于某个限制的人名。
这时你需要做两件事:把每个人映射成他们的名字,然后过滤掉其中那些不够短的名字。
这种情况可以用任何顺序应用map和filter操作。两种顺序得到的结果是一样的如下
>>> val people = listOf(Person("Alice",29),Person("Bob",31),Person("Charles",31),Person("Dan",21))
>>> println(people.asSequence().map(Person::name).filter{it.length < 4}.toList()) // 先 “map” 后 “filter”
[Bob,Dan]
>>> println(people.asSequence().filter{it.name.length < 4}
... .map(Person::name).tolist()) // 先“filter”后 map
[Bob,Dan]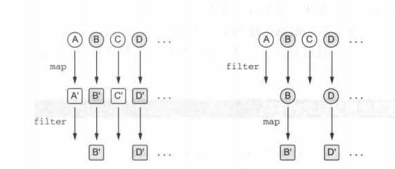
如果 filter 在强,不适合的元素会被尽早地过滤掉且不会发生变换。
5.3.2 创建序列
asSequence():函数用来在集合中创建序列
generateSequence()函数:给定序列中的前一个元素,这个函数会计算出下一个元素。
案例 使用 generateSequence 计算 100 以内所有的自然数之和。
>>> val naturalNumbers = generateSequence(0) {it +1} >>> val numbersTo100 = naturalNumbers.takeWhile{it <= 100} >>> println(numbersTo100.sum()) //当获得结果 “sum” 时,所有被推迟的操作都被执行 5050例子中 naturalNumbers 和 numbersTo100都有延期操作序列。这些序列中的实际数字知道你调用末端操作的时候才会求值。(sum)
创建父目录的序列
如果元素的父元素和它的类型相同(比如人类或者java文件),你可能会对它的所有祖先组成的序列的特质感兴趣。下列这个例子可以查询是否放在隐藏目录中,通过创建一个其父目录的序列并检查每个目录的属性来实现。
/* 创建并使用父目录的序列 */ fun File.isInsideHiddenDirectory() = generateSequence(this){it.parentFile}.any{it.isHidden} // 查询文件是否放在隐藏目录中。 >>> val file = File("/Users/svtk/.HiddenDir/a.txt") >>> println(file.IsInsideHiddenDirectory()) true你生成了一个序列,通过提供第一个元素和获取每个后续元素的方式来实现。如果把any换成find,你还可以得到你想要的那个目录(对象)。注意,使用序列允许你找到需要的目录之后立即停止遍历父目录。
5.4 使用 Java 函数式接口
Kotlin 的 lambda 可以和 Java API 互操作。
在本章节开头处,有看过一个把 lambda 传递给 Java 方法的例子:
button.setOnClickListener{/* 点击之后的动作 */} //复习 作为方法的最后一个参数可以省略()。把lambda作为实参传递。Botton 通过接收类型为OnClickListener的实参的setOnClickListener方法给按钮设置一个新的监听器:
/* Java */
public class Button{
public void setOnClickListener(OnClickListener l){...}
}OnClickListener 接口声明了一个方法,onClick:
接口可以被实现,但不能被实例化。
public interface OnClickListener{
void onClick(View v)
}在Java 8 之前你不得不创建一个匿名类的实例来作为实参传递给 setOnClickListener方法:
button.setOnClickListener(new OnClickListener(){
@Override
public void onClick(View v){
...
}
})在 kotlin 中 可以传递一个 lambda,代替这个实例:
button.setOnClickListener{view -> ...}lambda 用来实现 OnClickListener,它有一个类型为View的参数,和onClick一样。

这个方法可以工作的原因是OnClickListener接口只有一个方法。这种方法被称为函数式接口,或者 SAM 接口,SAM 代表单抽象方法。Java API随处可见像Runnable和Callable这样的函数式接口,以及支持它的方法。Kotlin允许你在调用接口函数式接口作为参数的方法时使用lambda,来保证你的Kotlin代码即整洁又符合习惯。
5.4.1 把lambda 当作参数传递给Java方法
可以把lambda传递给任何期望函数式接口的方法。
例如,如下的方法 Runable类型的参数:
/* Java */ void postponeComputation(int delay,Runnable computation);在 Kotlin 中,可以调用它并把一个lambda作为实参传给它。编译器会自动把它转换成一个Runnable的实例:
postponeComputation(1000){ println(42) }
当我们说“一个Runnnable的实例”时,指的是“一个实现了Runnable接口的匿名类的实例”。编译器会帮你创建它,并使用lambda作为单抽象方法–这个例子中式run方法–的方法体。
如下:显式的创建一个Runnable的匿名对象也能达到同样的效果:
postponeComputation(1000,object:Runnable{ //把对象表达式作为函数式接口的实现传递。 override fun run(){ println(42) } })但是这里有点不一样。当你显式地声明对象时,每次调用都会创建一个新的实例。使用lambda的情况不同:如果lambda没有访问任何来自定义它的函数变量,相应的匿名类实例可以在多次调用之间重(chóng)用:
postponeComputation(1000){println(42)} //整个程序只会创建一个Runnable的实例想要完全等价的实现应该是下面这段代码中的显式object声明,它把Runnable实例存储在一个变量中,并且每次调用的时候都使用这个变量:
val runnable = Runnable{println(42)} //编译成全局变量:程序中仅此一个实例 fun handleComputation(){ postponeComputation(1000,runnable) //每次postponeComputation调用时用的是一个对象 }如果lambda在包围它的作用域中捕捉到了变量,那么每次调用就不再可能重用同一个实例了。
这时,每次调用编译器都要创建一个新对象,其中存储着被捕捉的变量的值。
如下:每次调用都会使用一个新的Runnable实例,把id值存储在它的字段中:
fun handleComputation(id:String){ //lambda会捕捉“id”这个变量 postponeComputation(1000){println(id)} //每次handleComputation调用都创建一个Runnable的新实例。 }
Lmabda的实现细节
从 Kotlin1.0起,每次lambda表达式都会被编译成一个匿名类,除非它是内联lambda。(内联函数不会创建匿名类)。在后续版本支持生成java8字节码后,编译器就可以避免为每一个lambda表达式都生成一个独立的.class文件。如果lambda捕捉了变量,每个被捕捉的变量会在匿名类中有对应的字段,而且每次(对lambda)的调用都会创建一个这个匿名类的新实例。
否则,一个单例就会被创建。类的名称由lambda声明所在的函数名字称加上后缀衍生出来:这个例子中就是 HandleComputation$1。如果你反编译之前lambda表达式的代码,就会看到:
class HandleComputation$1(val id:String):Runnable{ override fun run(){ println(id) } } fun handleComputation(id:String){ postponeComputation(1000,HandleComputation$1(id)) //底层创建一个特殊的实例,而不是lambda }编译器给每个被捕捉的变量生成了一个字段和一个构造方法参数。
把lambda传给标记成 inline 的Kotlin函数,是不会创建任何匿名类的。
5.4.2 SAM构造方法:显式地把lambda转换成函数式接口
SAM构造方法是编译器生成的函数。用来让你执行从lambda到函数式接口实例的显式转换。
可以用在编译器不会自动应用转换的上下文中使用它。
例如:如果有一个方法返回一个函数式接口(只有一个抽象方法的实例)的实例,不能直接返回一个lambda,要用SAM构造方法把它包装起来。
如下例子:
/* 使用SAM构造方法来返回值 */ fun createAllDoneRunnable():Runnable{ return Runnable {println("All done!")} } >>> createAllDoneRunnable().run() All done!SAM(函数式接口)构造返回的名称和底层函数式接口的名称一样。SAM构造方法只接收一个参数— 一个被用作函数式接口单抽象方法的lambda – 并返回实现了这个接口类的一个实例。
除开返回值外,SAM构造方法还可以用在需要把从lambda生成的函数式接口实例存储在一个变量中的情况。**假设你要在多个按钮上重用同一个监听器**,就像下面的代码清单一样(在Android应用中,这段代码可以作为Activity.onCreate方法的一部分)
/* 使用SAM构造方法来重用listener实例 */ val listener =OnClickListener{ view -> val text = when (view.id){ R.id.button1 -> "First button" R.id.button2 -> "Second button" else -> "Unknown button" } toast(text) } button1.setOnClickListener(listener) button2.setOnClickListener(listener)listener 会检查那个按钮是点击的事件源并作出对应的行为。可以使用实现了OnClickListener的对象声明来定义监听器,但是SAM构造方法提供了更简洁的方法。
Lambda 和 添加/移除监听器
lambda 内部类有匿名对象那样的this:没有办法应用lambda转换成的匿名类实例。从编译器的角度来看,lambda是一个代码块,而不是一个对象,而且也不能当作一个对象来引用。Lambda中的this引用指向的是包围它的类。
- 如果你的事件监听器在处理事件时需要取消它自己,不能使用lambda这样做。这种情况使用实现了接口的匿名对象。在匿名对象内,this关键词指向该对象实例,可以把它传递给移除监听器的API
尽管方法调用中的SAM转换一般都会自动发生,但是当把lambda作为参数传给一个重载方法,也有编译器不能选择正确的重载情况。这时显式的SAM构造方法时解决错误的好方法。
5.5 带接收器的lambda:”with“ 与 ”apply“
带接收者的lambda:
此节将办理逐步熟悉Kotlin的lambda的独特功能:在lambda函数体类可以调用一个不同对象的方法,而却无需借助任何限定符;此方法在java中是不存在的。这样的lambda叫做带接收者的lambda
什么是带接收者的 lambda?
Kotlin 中独特的 lambda 功能:在lambda函数体内可以调用一个不同的对象方法,而且无需借助任何额外的限定符。
接收者:调用者
5.5.1 “with” 函数
从 with 函数开始它用到了带接收者lambda。
with的库函数:
它对同一个对象执行多次操作,而不需要反复把对象的名称写出来。
构建字母表
fun alphabet(): String {
val result = StringBuilder()
for (letter in 'A'..'Z') {
result.append(letter)
}
result.append("\n Now I know the alphbet!")
return result.toString()
}fun main() {
println(alphabet())
}
使用场景(为什么要用”with“)
案例中多次调用到 “result“实例。使用”with“减少对实例的调用。
如何使用 ”with“?
fun alphabet(): String {
val result = StringBuilder()
return with(result) {// 指定接收者的值
for (letter in 'A'..'Z') {
this.append(letter) // 显式的使用‘this’来调用接收者值的方法(result.appned()方法)
}
append("\n Now I know the alphabet!") // 隐藏 ‘this’ 同样可以使用
this.toString()
}
}fun main() {
println(alphabet())
}”with“的结构
with 结构看上去像是一种特殊的语法结构,但它实际上是一个接收两个参数的函数:这个例子中两个参数分别是 stringBuilder 和 lambda 。
with 函数把第一个参数转换为第二个参数传递给 lambda 的接收者。
在普通函数中与扩展函数中带接收者的 lambda 有那些不同
在扩展函数体内部,this 指向了这个函数扩展的那个类型实例,而且也可以被省略掉,让你直接访问接收者的成员。
上面的代码中,this 指定了stringBuilder,这时传给with的第一个参数。可以通过显式的this引用来访问stringBuilder的方法,就像this,append(latter)这样:也可以像append(”\nNow…”)
重构初始的alphabet函数,去除stringBuilder变量。
/* 使用with和一个表达式函数体来构造字母表 */ fun alphabet() = with(StringBuilder){ for(letter in 'A'...'Z'){ append(letter) } append("\n Now I know the alphabet!") toString() }现在此函数只返回一个表达式,所有表达式函数体语法重写了它。
可以创建一个新的StringBuilder实例直接当作实例传递给这个函数,然后 lambda中不需要显式的this就可以引用到这个实例。
5.5.2 “apply” 函数
apply 和 with 的不同
apply 函数同with 函数功能相同,区别在于 apply 始终会返回作为实参传递给它的对象。(返回本身作为实例)
fun alphabet() = StringBuilder().apply {
for (letter in 'A'..'Z') {
append(letter)
}
append("\n Now I know the alphbet!")
}.toString()apply 被声明成一个扩展函数。它的接收者变成了作为实参的 lambda 的接收者。执行 apply 的结果是StringBuilder,所以接下来里可以调用 toString 把它转换成 String。
使用apply初始化一个TextView
fun createViewWithCustomAttributes(context : Context) = {
TextView(context).apply{
text = "Sample Text"
textSize = 20.0
setPadding(10,0,0,0)
}
}apply函数允许里使用紧凑的表达式函数体风格。新的TextView实例创建之后立即被传给了apply。
那个是接收者?
TextView实例变成了 (lambda 的) 接收者,你可以调用它的属性和方法。
with 函数和 apply 函数是最基本和最通用的使用带接收者的 lambda 的例子。更多的函数也可以使用这种模式。例如,使用标准库函数buildString进一步简化alphbet函数,它会负责创建StringBuilder并调用toString。building实际是带接收者的lambda,接收者就是StringBuilder。
使用buildString创建字母表
/* 使用bulderString创建字母表 */
fun alphabet()=builderString{
for (letter in 'A'...'Z'){
append(latter)
}
append("\n Now I know tha alphabet!")
}buildString 函数完成了借助StringBuilder创建String的任务。
5.6 小结
- Lambda 允许你将代码块当作参数传递给函数。
- Kotlin可以把lambda放在括号括号外穿的给函数,而且可以使用it引用单个lambda参数
- lambda中的代码可以访问和修改包括这个lambda调用的函数的变量(访问修改调用者的变量)
- 通过在函数名称前加上前戳::,可以创建方法、可以创建方法及属性的引用,并用这些引用代替lambda传递给函数。
- 使用像filter、map、all、any、等函数,大多数公共的集合操作不需要手动迭代元素就可以完成。
- 序列允许你合并一个集合上的多个操作,而不需要创建新的集合来保存中间结果。
- 可以把lambda作为实参传递给接收Java函数式接口(带单抽象方法的接口,也叫SAM接口)作为形参的方法。
- with标准库函数允许你调用同一个对象的多个方法,而不需要反复写出这个对象的引用。apply函数让你使用构造者风格的API创建和初始化任何对象。
6 Kotlin的类型系统
6.1 可空性
可空性是Kotlin类型系统中帮助你避免NullPointerException错误的特性。
现代编程语言包括Kotlin解决这类问题的方法是把运行时的错误转变成编译期的错误。通过支持作为类型系统的一部分的可空性,编译器就能在编译器发现很多潜在的错误,从而减少运行时抛出异常的可能性。
我们会讨论Kotlin中的可空类型:Kotlin怎样表示允许null的值,以及Kotlin提供的处理这些值的工具。除此之外,我们还要讨论混合使用Kotlin和Java代码时关于可空类型的细节。
6.1.1 可空类型
Kotlin 和 Java 的类型系统之间第一条也可能是最重要的一条区别是,Kotlin对可空类型的显式的支持。
这意味着,这是一种指出你程序中那些变量和属性允许为null的方式。如果一个变量可以为null,对变量的方法的调用就是不安全的,因为这样会导致NullPointerException。Kotlin不允许这样的调用因而可以阻止许多可能的异常。
在实践时它是如果工作的
int strLen(String s){
return s.length();
}这个函数被调用的时候,传给它的是一个null实参,它会抛出NullPointerException。是否需要在方法中增加对null的检查,这取决于使用该函数的意图。
用Kotlin重写这个函数
不希望在调用时传递一个 null 进来
fun strLen(s:String) = s.length使用可能为null的参数调用strLen是不允许的,在编译期就会被标记成错误:
>>> strLen(null) ERROR:Null can not be a value of a non-null type String这个函数中的参数被声明成String类型,在Kotlin中这个表示它必须包含一个String实例。这一边由编译器强制实施,所以你不能传递一个包含null的参数。
如果你允许调用这个方法的时候传递给它可能所有的实参,包含那些可以为null的实参,需要显式地在类型名称后面加上问号来标记它:
fun strLenSafe(s:String?) = ... //允许为空问号可以加载任何类型的后面来表示这个类型的变量可以存储null引用:String?、Int?、MyCustomType?等等

所有类型在没有问号的类型声明的情况下是不能存储null引用的,也就是说常见类型默认都是非空的。
在拥有一个可空类型的值,能对它进行操作也是有限制的。
例如,不能再调用它的方法:
>>> fun strLenSafe(s:String?) = s.length() ERROR:only safe(?.) or non-null asserted (!!.) calls are allowed on a nullable receiver of type kotlin.String?也不能再把它赋值给非空类型的变量:
>>> val x:String ?= null >>> var y:String =x ERROR:Type mismatch:inferred type is String? but String was expected也不能把可空类型的值传递给拥有非空类型参数的函数:
>>> strLen(x) ERROR:Type mismatch:inferred type is String? but String was expected可以进行的操作
最重要的操作就是和null进行比较。而且一旦你进行了比较操作,编译器就会记住,并且在这次比较发生的作用域内把这个值当作非空来对待。
例如,下列代码是合法的:
/* 使用 if 检查处理null */ fun strLenSafe(s:String?):Int = if (s != null) s.length else 0 // 增加了null 检查后,这段代码就可以编译了 >>> val x:String?= null >>> println(strLenSafe(x)) 0 >>> println(strLenSafe("abc")) 3if 检查并不是唯一处理可空性的工具,稍后会有其他工具来帮助我们处理可空值。
6.1.2 类型的含义
什么是类型,为什么变量拥有类型?
类型就是数据的分类,决定了该类型可能的值,以及该类型的值上可能完成的操作(维基百科)。
试试在Java的一些类型上套用如上的定义,从double类型开始。double类型是64位的双精度浮点数。可以对double类型的值进行标准的算术运算,所有的功能都可以一视同仁的运用到所有double类型的值上。因此如果你有一个类型为double的变量,那么你就能确定编译器允许在该值上进行任意操作,都可以被成功的执行。
现在我们把它和String类型的变量对比一下。在Java中,这样的变量可以持有两种值,分别是String实例和null。这两种完全不一样:就连Java自己的instanceof运算符都会告诉你null不是String。这两种值的操作也完全不一样:真实的String实例允许你调用它的任何方法,而null值只允许非常有限的操作。
上述表明在Java中类型系统不能很好的工作。即使变量拥有声明类型String你依然无法知道能对该变量的值做些什么,除非做额外的检查。你往往跳过这些检查,因为你觉得你了解程序中大概的数据流动,并确定在某个点上的值不可能为null。有时候你想错了,而你的程序就会因为NullPointerException而崩溃。
Kotlin的可空类型为这类问题提供了全面的解决方案。区分开可空类型和非空类型使事情变得明朗:那些对值的操作使允许的,哪些操作有会导致运行时异常并因此被禁止。
注意:
可空的和非空的对象在运行时没有什么区别;可空类型并不是非空类型的包装。所有的检查都发生在编译期。这意味Kotlin的可空类型并不会在运行时带来额外的开销。
6.1.3 安全调用运算符:“?.”
安全调用运算符:“?.”,它允许你把null检查和一次方法复用合并成一次操作。
例如:表达式 s?.toUpperCase() 等用于下面这种繁琐的写法: if (s!=null) s.toUpperCase() else null。
也就是说在你调用一个非空值的方法,这次方法调用会被正常的调用。如果是null值的话,这次调用不会发生,而整个表达式的值为null。
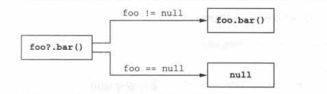
注意,这次调用的结果类型也是可空的。尽管String.toUppferCase()会返回String类型的值,但s是可空的时候,表达式s?.toUpperCase()的结果类型是String?:
fun printAllCaps(s:String?){
val allCaps:String? = s?.toUppperCase() // allCaps可能是null
println(allCaps)
}
>>> printAllCaps("abc")
ABC
>>> printAllCaps(null)
null安全调用不光可以调用方法,可能用来访问属性。
/* 使用安全调用处理可控属性 */
class Employee(val name:String,val manager:Employee?)
fun managerName(employee:Employee):String?= employee.maneger?.name
>>> val ceo = Employee("Da Boss",null)
>>> val developer = Employee("Bob Smith",ceo)
>>> println(managerName(developer))
Da Boss
>>> println(managerName(ceo))如果你的对象途中又多个可空类型的属性,通常可以在同一表达式中方便地使用多个安全调用。加入你要使用不同的类型来保存关于个人的信息、他们的公司,以及公司的地址,而公司和地址都可以省略。使用?.运算符,不需要任何额外的检查,就可以在以放代码中访问到Person的country属性。
/* 链接多个安全调用 */
class Address(val streetAddress:String,val zipCode:Int,val city:String,val country:String)
class Company(val name:String, val address:Address?)
class Person(val name:String,val company:Company?)
fun Person.countryName():String{
val country = this.company?.address?.country // 多个安全调用链接在一起
return if (country!=null) contry else "Unknown"
}
>>> val person = Person("Dmitry",null)
>>> println(person.countryName())
Unknown6.1.4 Elvis 运算符:“?:”
Kotlin有方便的运算符来提供代替null的默认值。它被称为Elvis运算符。(或者null合并运算符,或空合并运算符)
及不为null时运算左侧,null时运算右侧。
fun foo(s:String?){
val t:String = s?:"" //如果“s”为null,结果为空字符串
}Elvis运算符接收两个运算数,如果第一个运算数不为null,或者结果就是第一个运算数;如果第一个运算数为null,运算结果就是第二个运算数。
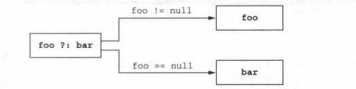
Elvis 运算符经常和安全调用运算符一起使用,用一个值代替null对象调用返回时返回null。
fun strLenSafe(s:String?):Int = s?.length?:0 >>> println(strLenSafe("abc")) 3 >>> pritnln(strLenSafe(null)) 0
在 6.1.3 “链接多个安全调用” 的函数 countryName现在也可以使用一行代码来完成。
fun Person.countryName()=conpany?.address?.country?:="Unknown"**
在Kotlin中有种场景下Elvis运算符会特别顺手,想return和throw这样的操作其实是表达式,因此可以把它们写在Elvis运算符的右边。这种情况下,如果Elvis运算符左边的值为null,函数就会立即返回一个值或者抛出一个异常,如果函数中需要检查先决条件,这个方式会很有用。
实现一个打印包含个人公司地址的出货标签函数。
/* 同时使用throw和Elvis运算符 */
class Address(val streetAddress:String,val zipCOde:Int,val city:String,val country:String)
class Company(val name:String,val address:Address?)
class Person(val name:String,val company:Company?)
fun pritnlnShippingLabel(person:Person){
val address = person.company?.address
?: throw IllegalArgumentException("No address") //如果缺少addres就抛出异常
with(address){ //address 不为空
println(streetAddress
println("$zipCode $city,$country")
}
}
>>> val address = Address("Elsestr. 47",80687,"Munich","Germany")
>>> val jetbrains = Company("JetBrains",address)
>>> val person = Person("Dmitry",jetbrains)
>>> printShippingLabel(person)
Elsestr.47
80687 Munich.Germany
>>> printShippingLable(Person("Alexey",null))
java.lang.IllegalArgumentException:No address如果一切正常,函数printShippingLable会打印出标签。如果地址不存在,它不会只是抛出一个带行号的NullPointerException,相反,它会报告一个有意义的错误。如果地址存在,标签会包含街道地址、邮编、城市和国家。留意之前说过的with函数是如何被用来避免在一行中重复四次address的。
6.1.5 安全转换 “as?”
“as”用来转换类型的常规Kotlin运算符,和常规的Java类型转换一样,如果被转换的值不是你试图转换的类型,就会抛出ClassCastException异常。
“as?”运算符尝试把值转换成指定的类型,如果值不是合适的类型就返回null
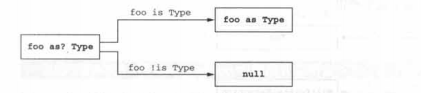
一种常见的模式是把安全转换和Elvis运算符结合使用。
/* 使用安全转换实现equals */
class Person(val firstName:String,val lastName:String){
override fun equals(o:Any?):Boolean{
val otherPerson = o as? Person ?: return false // 检查类型,如果不匹配就返回false
return otherPerson.firstName == firstName && otherPerson.lastName == lastName //在安全转换之后,变量otherPerson被智能地转换为 Person 类型
}
override fun hashCode():Int = firstName.hashCode() * 37 + lastName.hashCode()
}
>>> val p1 = Person("Dmitry","Jemerov")
>>> val p2 = Person("Dmitry","Jemerov")
>>> println(p1 == p2)
true
>>> println(p1.equals(42))
false使用这种模式,可以非常容易地检查实参是否是适当的类型,转换它,并在它的类型不能确定是返回false,而且这些操作全部在同一个表达式中。当然,这种场景下智能转换也会生效:当你检查过类型并拒绝了null值,编译器就确定了变量otherPerson值的类型是Person并当你能够相应的使用它。
6.1.6 非空断言:“!!”
非空断言:
它使用双感叹号表示,可以把任何值转换成非空类型。如果对null值做非空断言,则会抛出异常。
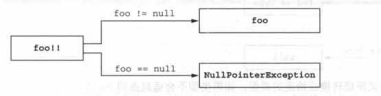
使用非空断言来吧可空的实参转换成非空。
/* 使用非空断言 */
fun ignoreNulls(s:String?){
val sNotNull:String = s!! // 异常指向这一行
println(sNotNull.length)
}
>>> igoreNulls(null)
Exceptin in thread "main" kotlin.KotlinNullPointerException
at <...>.ignoreNulls(07_NotnullAssertions.kt:2)如果上面函数中s为null会发生什么?Kotlin没有其他选择,它会在运行时抛出一个异常(一种特殊的NullPointerException)。但是注意异常抛出的位置是非空断言所在的哪一行,而不是接下来试图使用那个值的一行。本质上,你在告诉编译器:“我知道这个字不为null,如果我错了我准备好啦接收这个异常。”
注意:Kotlin的设计者试图说服你思考更好的解决方案,这些方案不会使用断言这种编译器无法验证的方法。
但是确实存在这种情况,某些问题适合使用非空断言来解决。当你在一个函数中检测一个值是否为null,而在另一个函数中使用这个值时,这种情况下编译器无法识别这种用法是否安全。(也就是使用前检查他是否为null)
使用情况
在确定你的变量非空时推荐使用它。因为在null状态下它会报出空指针异常。
6.1.7 “let” 函数
用来处理可空表达式。和安全调用运算符一起使用,允许你对表达式求值,检查求值结果是否null,并把结果保存为一个变量。
其中在let的匿名函数中it表示email字符串本身。
/* 使用let调用一个接收非空参数的函数 */
fun sendEmailTo(email : String){
println("Sending emaill to $emaill")
}
>>> var email:String ? = "yole@example.com"
>>> email?.let{sendEmailTo(it)}
Sending email to yole@example.com
>>> emaill = null
>>> emaill?.let{ sendEmailTo(it) }所以说只有这段表达式不为空时才会执行代码块里的代码
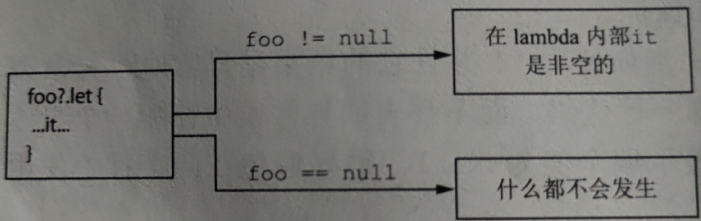
6.1.8 延迟初始化的属性
使用延迟初始化属性的原因
Kotlin 通常要求你在构造方法中初始化所有属性,如果某个属性是可空类型,你就必须提供一个非空的初始化值。否则,你就必须使用可空类型。如果你这样做,该属性的每一次访问都需要null检查或者”!!”运算符
使用非空断言访问可控属性
/* 使用非空断言访问可空属性 */
class MyService{
fun performAction():String = "foo"
}
class MyText{
private var myService : MyService ?= null // 声明了一个可空类型初始化为 null
@Before fun setUp(){ // 在 setUp方法中提供真正的初始化器
myService = MyService()
}
@Test fun testAction(){
Assert.assertEquals("foo",myService!!.performAction()) // 必须注意可空性:要么用"!!",要么用"?."
}
}/* 使用延迟初始化属性 */
class MyService{
fun performAction():String = "foo"
}
class MyText{
private lateinit var myService : MyService // 声明了一个不需要初始化器的非空类型属性
@Before fun setUp(){ // 在 setUp 方法中初始化 myService
myService = MyService()
}
@Test fun testAction(){
Assert.assertEquals("foo",myService.performAction()) // 不需要 null 检查直接访问属性
}
}注意
初始化的属性必须为var,因为需要在构造方法外修改它的值,使用val属性被编译时必须在构造方法中初始化final片段。
尽管 myService 属性是非空的,你不需要在构造方法中初始化它。在属性没有被初始化之前调用会得到异常 “lateinit property myService has not been initialized”。
lateinit 属性常见的一种用法是在依赖注入。在某种情况下,lateinit 属性的值是被依赖注入框架从外部设置的。为了保证和各种依赖注入框架的兼容性
,Kotlin 会自动生成一个和 lateinit 属性具有相同可见性的字段。如果属性的可见性是public,生成字段也是可见性public
6.1.9可空类型的扩展
为可空类型定义扩展函数。可以允许接收者(调用者)为空null 的(扩展函数)调用,并在该函数中处理null,而不是在确保变量不为null之后再调用它的方法。
只有扩展函数才能做到这一点,普通成员方法的调用是通过对象实例来分发的,因此实例为null时(成员方法)永远不能被执行。
Kotlin标准库中定义的String的两个扩展函数isEmpty和isBlanck就是这样的例子。第一个函数判断字符串是否是一个空的字符串“”。第二个函数则判断它是否是空的或者它只包含空白字符。通常用这些函数来检查字符串中是否有价值的,以确保对它的操作是由意义的。
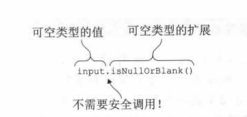
像这种无意义的空字符串和空白字符串这样处理null也很有用。事实上,你的确可以这样做:函数isEmptyOrNull和isNullOrBlank就可以由String?类型的接收者调用(用于可空类型接收者调用)。
/* 用可空接收者调用扩展函数 */
fun verifyUserInput(input:String?){
if (input.isNullOrBlank()){ //不需要安全调用
println("Please fill in the requied fileds")
}
}
>>> verifyUserInput(" ") //可空类型的扩展函数在接收者为空时也可以调用
Please fill in the required fields
>>> verifyUserInput(null)
Please fill in the required fields不需要安全访问,就可以直接为可控接收者声明扩展函数
函数isNullOrBlank显式地检查了null,这种情况下返回true,然后调用isBlank,它只能在非空String上调用:
fun String?.isNullOrBlank():Boolean = //可空字符串的扩展
this == null || this.isBlank //第二个“this”使用了智能转换当你为一个可空类型(以?结尾)定义扩展函数时,这意味着你可以对可空的值调用这个函数;并且函数体中的this可能为null,所以你必须显式地价差。在Java中,this永远是非空的,因为它引用的时当前你所在这个类的实例。而在Kotlin中,这并不永远成立:在可空类型的扩展函数中,this可以是null的。
let函数也能被可空的接收者调用,但它并不检查值是否为null。如果你在一个可空类型上调用let函数,而没有使用安全调用运算符,lambda的实参将会是可空的:
(let检查是否为null,并把结果保存为一个变量)
>>> val person:Person?=... // 可空类型的非空属性 >>> person.let{ sendEmailTo(it) } // 没有安全调用,所以“it”是可空类型 ERROR:Type mismatch:inferred type is Person? but Person was expected使用let来检查非空的实参,必须使用安全调用运算符“?.”,就像代码:person?.let{ sendEmailTo(it) }。
当你定义自己的扩展函数时,需要考虑该扩展是否需要为可空类型定义。默认情况下,应该把它定义成会空类型的扩展函数。在发现大部分情况下需要在可空类型上使用这个函数,再安全的修改它。
6.1.10 类型参数的可空性
Kotlin 中所有泛型类和泛型函数的类型参数默认都是可空的。
任何类型,包括可空类型在内,都可以替换类型参数。这种情况下,使用类型参数作为类型的声明都允许为null,尽管类型参数T并没有用问号结尾。
例子:
/* 处理可空的类型参数 */
fun <T> printHashCode(t:T){
println(t?.hashCode()) //因为”T“ 可能为null,所以必须使用安全调用
}
>>> printHashCode(null) //”T“被推导为”Any?“
null在printHashCode调用中,类型参数T推导出的类型是可空类型Any?。 因此,尽管没有用问号结尾,实参t依然允许持有null。
要使类型参数非空(不为空)必须要为它指定一个非空的上界,那样泛型就会拒绝可空值作为实参。
/* 为类型参数声明非空三界 */
fun <T:Any> printHashCode(t:T){ //现在”T“就不是可空的
println(t.hashCode())
}
>>> printHashCode(null) //这段代码是无法编译的:你不能传递null,因为期望值是非空值。
Error:Type paramater bound for 'T' is not asthisfied
>>> printHashCode(42)
42注意必须使用问号结尾来标记类型为可空的,没有问号就是非空的。类型参数是这个规则唯一的例外。(在使用三界后,想使用可空类型就要加问号来标记可空。)
6.1.11 可空性和Java
Kotlin 引以为傲的是和Java的互操作性,而你知道Java类型系统是不支持可空性的。在你混合使用Kotlin和Java时会发生什么?会不会失去所有的安全性?或者每个值都必须检查是否为null?
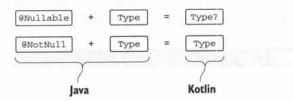
有些时候Java代码包含了可空性的信息,这些信息用注解来表达。
当代码中出现了这些信息时,Kotlin就会使用。因此Java中@Nullable string 被Kotlin当作String?(可空类型),而@NotNull String就是String(不为空类型)
Kotlin 可以识别多种不同风格的可空性注解,包括JSR-305标准的注解(在javax.annotation包之中)、Android的注解(android.support.annotation包之中)和JetBrains工具支持的注解(org.jetbrains.annotation)。
如果这些注解不存在会发生什么?
Java 类型会变成Kotlin中的平台类型
平台类型
平台类型本质上就是Kotlin不知道可空性信息的类型。即可以把它当作可空类型处理,也可以当作会空类型处理。

这意味着,你要像在Java中意义,对你在这个类型上做的操作负全部责任。编译器将会允许所有的操作,它不会把对这些字的空安全操作高亮多余的,但它平时确实这样对待会空类型值上的空安全操作。如果你认为这个字为null,在使用它之前可以用它和null进行比较。如果你认位它不为null,就直接使用它。就像在Java中一样,如果你错误地理解了这个值,使用的时候就会遇到NullPointerException。
例子
/* 没有可空性注解的Java类 */
public class Person{
private final String name;
public Person(String name){
this.name = name
}
public String getName(){
return name
}
}getName能不能返回null?这种情况下Kotlin编译器完全不知道String类型的可空性,所以你必须处理它。如果你确定name不为null,就可以像Java中一样按照通常的方式对它解引用,不需要额外的检查。但是这种情况下请准备好接受异常。
/* 不使用null检查访问Java类 */
fun yellAt(person:Person){
println(person.name.toUpperCase()+ "!!!" ) //toUpperCase()调用的函数接收者person.name为null,所以这里会抛出异常
}
>>> yellAt(Person(null))
java.lang.IllegalArgumentException:Paramater specified as non-null is null: method toUpperCase, parameter $receiver注意,这里你看到的不是一个NullPointerException,而是一条更详细的错误信息,告诉你方法toUpperCase不能在null的接收者上调用。
对于公有的Kotlin函数,编译器生成对每个非空类型的参数(和接收者)的检查和,所以使用不正确的参数的调用尝试都立即被报告为异常。(在使用参数前会检查非空的参数。)
这种值检查在函数调用的时候就执行,而不是等到这些参数被使用的时候。这确保了不正确的调用会被尽早的发现,那些由于null值被传给代码不同层次的多个函数之后,并被这些函数访问时而产生的难以理解的异常就能被避免。
把getName()的返回类型解释为可空的并安全的访问它。
/* 使用null检查来访问的Java类 */
fun yellAtSafe(person:Person){
println((person.name?:"Anyone").toUpperCase()+"!!!")
}
>>> yellAtSafe(null)
ANYONE!!!Java API 中大部分库没有(可空性)注解,所以可以把所有类型都解释为非空,但是会导致错误。为了避免错误,你应该阅读Java方法的文档(必要时还要查看它的实现),并知道它上面时候返回null,并给那些返回加上检查。
为什么需要平台类型?
对 Kotlin 来说,把来自Java的所有值都当成可空的是不是更安全?这种设计也许可行,但是这需要对永远不为空的值做大量冗余的null检查,因为Kotlin编译器无法了解到这样的信息。
涉及泛型的话这种新款就更加糟糕了。例如,在Kotlin中,每次来自Java的ArrayList
都被当作ArrayList<String?>?,每次访问或者转换类型都需要检查这些值是否为null,这样抵消掉安全性带来的好处。编写这样的检查非常令人厌烦,所以Kotlin的设计者做出了更实用的选择,让开发者负责正确处理来自Java的值
在Kotiln中不能声明一个平台类型(不知道可空信息的)的变量,这些信息只能来自Java代码,但你可能会在IDE的错误信息中见到它们。
>>> val i:Ine = person.name
ERROR:Type mismatch: inferred type is String! but Int was expectedString! 表示法被Kotlin编译器用来表示来自Java代码的平台类型。你不能在自己的代码中使用这种语法。而且感叹号通常与问题的来源无关,所以通常可以忽略它。这只是在强调类型的可空性是未知的。
你可以用你喜欢的方式来解释平台类型,既可以是可控的也可以是非空的。
>>> val s:String?=person.name //可空
>>> val s1:String = person.name //非空如果你用来自Java的null值给一个非空的Kotlin变量赋值,在赋值的瞬间你就会得到异常。你需要正确的理解可空性。
继承
Kotlin 重写Java的方法时,可以选择把参数和返回类型定义成可空的,也可以选择把它们定义成非空的。
例子
/* Java中的StringProcessor接口 */
interfece StringProcessor{
void process(String value);
}Kotlin 中下面的两种实现编译器都可以接收。
/* 实现Java接口时使用不同的参数可空性 */
class StringPrinter:StringProcessor{
override fun process(value:String){
pritlin(value)
}
}
class NullableStringPrinter:StringProcessor{
override fun process(value:String?){ // 参数可空
if(value != null){
println(value)
}
}
}在实现Java类或者接口的方法时一定要搞清楚它的可空性。因为方法实现可在非Kotlin的代码中被调用,Kotlin编译器会为你声明的每个非空的参数生成非空断言。如果Java代码传给这个方法一个null值,断言就会触发,你就会得到一个异常,即便你从来没有在你的实现中访问过这个参数的值。
6.2 基本数据类型和其他基本类型
描述程序中的基本数据类型,例如Int、Boolean和Any。
与Java不同,Kotlin并不区分基本数据类型和它们的包装类。
6.2.1 基本数据类型:Int、Boolean及其他
Java把基本数据类型和引用类型做了区分。
一个基本数据类型(如int)的变量直接存储了它的值,而一个引用类型(如String)的变量存储的时指向包含该对象的内存地址的引用。
基本数据类型的只能够更高效地存储和传递,但你不能对这些值调用方法,或是它们存放在集合中。
Java提供了特殊的包装类型(比如java.lang.Integer),在你需要对象的是否对基本数据类型进行封装。因此,你不能用Collection
来定义一个整数的集合,而必须用Collection 来定义。
Kotlin 并不区分基本数据类型和包装类型,永远是同一个类型(比如int)
val i:Int = 1 val list:List<Int> = listOf(1,2,3)同时还能对数字类型的值调用方法。
/* 使用标准库的函数coerceIn来把值限制在特定范围内 */ fun showProgress(progress:Int){ val percent = progress.coerceIn(0,100) println("We're ${percent}% done!") } >>> showProgress(146) We're 100% done!虽然没有区分基本数据类型和包装类型,但是这不意味着Kotlin使用对象来表示所有数组!
在运行时,数字类型会尽可能地使用最高效的方式来表示。大多数形况下——对于变量、属性、参数和返回类型——Kotlin的Int类型会被编译成Java基本类型int。唯一不可行的例外是泛型类,例如集合。用作泛型参数的基本数据类型会被编译成对应的包装类。例如,Int类被用作集合类型的类型参数时,集合类将会保存对应包换类型java.lang.Integer的实例。
Java基本数据类型完整列表
- 整数类型——Byte、Short、Int、Long
- 浮点整数类型——Float、Double
- 字符类型——Char
- 布尔类型——Boolean
就像Int 这样的Kotlin类型在底层可以轻易的编译成对应的Java基本类型,因为两种类型都不能存储null引用。当你在Kotlin中使用Java声明时,Java基本数据类型就会变成非空类型(而不是平台类型),因为它们不能持有null值。
6.2.2 可空基本数据类型:Int?、Boolean?及其他
Kotlin中的可空类型不能用Java的基本数据类型表示,因为null只能被存储在Java的引用类型的变量中。这意味着任何时候使用了基本数据类型的可空版本,它就会被编译成对应的包装类。
/* 名字永远已知的Person类,但是年龄可能未知或者未指定。添加函数检查一个人是否比另一个人年长 */
class Person(val name:String,val age:Int ?= null){
fun isOlderThan(other:Person):Boolean?{
if(age == null ||other.age == null)
return null
return age > other.age
}
}
>>> println(Person("Sam",35).isOlderThan(Person("Amy",42)))
false
>>> println(Person("Sam",34).isOlderThan(Person("Jane")))
null注意,普通的可空性规则如何在这里引用。你不能就这样比较两个值,因为它们当中任何一个都可能为null。你必须检查两个值都不为null。
Person类声明的age属性的值被当作java.lang.Integer存储(包装类)。但是只有在你使用来自Java的类时这些细节才有意义。为了在Kotlin中选出正确的类型,你只需要考虑对变量或者属性来说,null是否是它们可能的值。
泛型类(ArrayList
创建一个Integer包装类的列表,尽管没有指定过可空类型或者用过null值
val listOfInts = listOf(1,2,3)这是由Java虚拟机实现泛型的方式决定的。JVM不支持用基本数据类型作为类型参数,所以泛型类(Java和Kotlin一样)必须始终使用类型的包装表示。因此,你要高效的存储基本数据类型元素的大型集合,要么使用支持这种集合的第三方库(如Trove4J)要么使用数组来存储。
6.2.3 数字转换
Kotlin和Java之间一条重要的区别就是处理数字转换的方式。Kotlin不会自动的把数字从一种类型转换成另一种,即便是转换范围更大的类型。
val i = 1
val i : Long = i //错误:类型不匹配正确的转换
val i = 1
val l:Long = i.toLang()基本数据类型类型(Boolean除外)都定义有转换函数:toByte()、toShort()、toChar()等。这些函数支持双向转换:既可以把 小范围的类型扩展到大范围,比如Int.toLong(),也可以把大范围的类型截取到小范围,比如Long.toInt()。
Kotlin 要求转换必须是显式的,尤其是在比较装箱值的时候。比较两个装箱值的equals方法不仅会检查它们存储的值,还会比较装箱类型。所以,在Java中new Integer(42).equals(new Long(42)) 会返回false。
Java中的装箱和拆箱
装箱和拆箱是从Java1.5开始引入的,它的目的是将原始类型值自动地转换成对应的对象。自动装箱机制可以让我们在Java的变量赋值或者其他方法调用等情况下使用原始类型或者对象类型更加简单直接。
假如 Kotlin 支持隐式转换,
val x = 1 // Int变量
val list = listOf(1L,2L,3L) //Long值列表
x in list //假如支持隐式转换它仍然是 false因此,上列中 x in list 根本不会编译。Kotlin要求你显式的转换类型,这样只有类型相同的值才比较:
>>> val x = 1 >>> println(x.toLong() in listOf(1L,2L,3L)) true在代码中用到不同的数据类型,你必须显式的转换这些变量,来避免意想不到的结果。
基本数据类型字面值
- 使用后戳L表示Long类型(长整型)字面值:123L.
- 使用标准浮点数表示Double(双浮点精度)字面值:0.12、2.0、1.2e10、1.2e-10。
- 使用F表示Float类型(浮点数)字面值:123.4f、.345F、1e3f。
- 使用前戳0x或者0X表示十六进制字面值:0xCAFEBABE或者0xbcdL。
- 使用前戳0b或者0B表示二进制字面值:0b000000101.
在Kotlin1.1才开始支持数字字面值中的下划线。对字符字面值来说,可以使用和Java几乎一样的语法。把字符卸载单引号中,必要时还可以使用转义序列。有效的Kotlin字符字面值:‘1’、‘/t’(制表符)、‘\u0009’(使用Unicode转义序列表示的制表符)。
当你在书写数字字面值的时候,一般不需要使用转换函数。这种(字面值)特殊的语法来显示地标记常量类型,例如42L或者42.0f。即使你没有使用这种语法,数字字面值去初始化一个类型已知的变量是(Ine 类型已知,初始化为Long),又或是把字面值当作实参传递给函数时,必要的转换会自动发生。 算数运算符也会被重载,它们可以接收所有适当的数字类型。
/* 如下的代码并没有任何显式的转换却可以正常工作过 */ fun foo(l:Long) = println(l) >>> val b:Byte = 1 //常量有正确的类型 >>> val l = b+1L //+可以进行直接类型和长整型参数的计算 >>> foo(42) // 编译器认为42是一个长整型 42Koylin算术运算符关于数值范围溢出的行为和Java完全一直;Kotlin并没有引入由溢出检查带来的额外开销。
字符串转换
Kotlin 标准库提供了一套相似的扩展方法,用来把字符串转换成基本数据类型(toInt、toByte、toBoolean、等)。
>>> println("42".toInt()) 42函数会尝试把字符串的内容解析成对应的函数,如果解析失败抛出NumberFormatException。
6.2.4 “Any”和“Ant?”:根类型
和Ojbect作为Java类层级结构的根差不多,Any类型是Kotlin所有非空类型的超类型(非空类型的根)。而在Java中,Object只是所有应用类型的超类型(引用类型的的根),而基本数据类型并不是类层级结构的一部分。这意味着当你需要Object的时候,不得不使用java.long.Integer这样的包装类型来表示基本数据类型的值。而在Kotlin中,Any是所有类型的超类型(所有类型的根),包括像Int这样的基本数据类型。
基本数据类型的值赋给Any类型的变量时会自动装箱:
val answer:Any = 42 \\Any是引用类型,所以值42会被装箱Any是非空类型,所以Any类型的变量不可以持有null值。Kotlin中想要持有任何可能的变量,包括null在内,必须使用Any?类型。
在底层,Any类型对应java.lang.Object。Kotlin把Java方法参数和返回类型中用到的Object类型看作Any(更确切的说是当作平台类型,因为其可空性是位置的)。当Kotlin函数使用Any时,它会被编译成Java字节码中的Object。
这是匿名函数在使用两种不同的类型作为返回时自动使用Any类型。
val printNumberReturn = { numberInt: Int -> when (numberInt) { 1 -> "输入1返回字符1" 2 -> "输入2返回字符2" 3 -> "输入3返回字符3" 4 -> "输入4返回字符4" 5 -> "输入5返回字符5" 6 -> "输入6返回字符6" 7 -> "输入7返回字符7" else -> -1 } } println(printNumberReturn(7)) println(printNumberReturn(10)) ------------------------------ 输入7返回字符7 -1
6.2.5 Unit 类型:Kotlin的“void”
Kotlin中的Unit类型和Java中void是一样的功能。在函数没有什么需要返回的时候,Unit可以用作函数的返回类型:
fun f(): Unit{...}
fun f(){...} //省略Unit声明两个代码块的结果是相同的。
大多数情况下你不会留意到void和Unit之间的区别。如果你的Kotlin函数使用Unit作为返回类型并且没有重写泛型函数,在底层它会被编译成旧的void函数。如果你要在Java中重写这个函数,新的Java函数需要返回void。
Kotlin中的Unit和Java中的void到底有那些不同?
Unit是一个完整的类型,可以作为类型参数,而void却不行。只存在值是Unit类型,这个值也叫Unit,并且会被隐式地返回。当你在重写返回泛型参数的函数
时会非常有用只需要让方法返回Unit类型的值:
interface Processor<T>{ fun process():T } class NoResultProcessor:Processor<Unit>{ override fun process(){ // 返回 Unit ,这里可以省略类型说明 // do stuff } // 这里不需要显式的return }接口签名要求process函数返回一个值;而且,因为Unit类型确实有值,所以从方法中返回它并没有问题。然而你不需要在NoResultProcessor.process函数中写上显式的return语句,因为编译器会隐式地加上return Unit.
在与Java对比中,Java中为了解决使用“没有值”作为类型参数的任何一个可能解法,都没有Kotlin好用。一种是分开接口定义来表示需要和不需要返回值的接口(如Callable和Runnable)。另一种使用特殊的java.lang.Void类型作为类型参数。即便你使用了后面这种方法,你还是需要加入return null;语句来返回唯一能匹配这个类型的值,因为只要返回类型不是void,你就必须始终有显式的return语句。
在函数式编程语言中,Unit这个名字习惯上被用来表示“只有一个实例”,这正是Kotlin和Java的void的区别。
6.2.6 Nothing类型:“这个函数永不返回”
解释了为什么要创建Nothing类型
对于某些Kotlin函数来说,“返回类型的概念没有任何意义,因为它从来不会成功地结束。例如,许多测试库都有一个叫fail的函数,它通过抛出带有特定信息的异常来让当前测试失败。一个包含无限循环的函数也永远不会成功地结束。
分析调用函数代码时,知道函数永远不会正常结束是很有帮助的。Kotlin 使用Nothing这种特殊的返回类型来表示:
fun fail(message:String):Nothing{
throw IllegalStateException(message)
}
>>> fail("Error occurred")
java.lang.IllegalStateException:Error occurredNothing 类型没有任何值,只有被当作函数返回值使用,或者被当作泛型函数返回值的类型参数使用才会有意义。在其他情况下,声明一个不能存储任何值的变量是没有意义的。
Nothing函数可以放在Elvis运算符的右边来做先决条件检查:
val address = company.address?:fail("No address")
println(address.city)编译器知道这种返回类型的函数从不终止,然后在分析调用这些函数的代码时利用这个信息。上例,编译器会把address的类型推断成非空,因为它为null时的分支处理会始终抛出异常。
6.3 集合与数组
Kotlin以Java集合库为基础构建,并通过扩展函数增加的特性来增强它。
6.3.1 可空性和集合
我们讨论了可空类型的概念,但仅仅简略的谈到类型参数的可空性。对前后一致的类型系统来说十分关键:知道集合是否可以持有null元素,和知道变量值是否可以为null同等重要。Kotlin完全支持类型参数的可空性。就像变量的类型可以加上?字符来表示变量可以持有null一样,类型在被当作类型参数时也可以用同样的方式标记。
这个函数从一个文件中读取文本行的列表,并尝试把每一行文本解析成数字。
/* 创建一个可以包含可空值的集合 */
fun readNumbers(reader: BufferedReader): List<Int?>{
var result = ArratList<Int?>() //创建包含可空Int值的列表
for (line in reader.lineSequence()){
try{
val number = line.toInt()
result.add(number) // 向列表中添加整数(非空)
}
catch(e: NumberFormatException){
result.add(null) //向列表添加 null,因为当前行不能被解析成整数。
}
}
return result
}如果这一行文本被解析,那么就向result列表中添加一个整数,否则添加null。List<Int?>是能持有Int?类型值的列表:换句话说,可以持有Int或者null。(集合中可以存放null值)。从Kotlin1.1中,可以使用函数String.toIntOrNull来简化例子,字符串不能被解析的时候会返回null。
变量自己的可空性和用作类型参数的类型的可空性是有区别的。包含可空Int的列表和包含Int的可空列表之间是有区别的。如下:
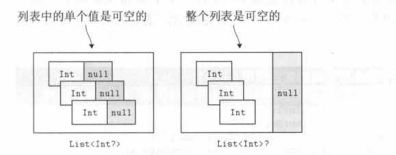
第一种情况,列表本身始终不为null,列表中的每个值都可以为null。第二种类型的变量可能包含空引用而不是列表实例,但列表中的元素始终保持非空的。
在另一种上下文中,你可能需要声明一个持有可空的列表,并且包含可空的数字。Kotlin中的写法是List<Int?>?,有两个问号。在使用变量自己值的时候,以及使用列表中每个元素的时候,需要使用null检查。(因为内容可能为空,所以在使用时需要做null检查)
如何使用可空值的列表,如下函数计算列表中有效数字之和,并单独的对无效数字计数。
/* 使用可空值集合 */
fun addValidNumbers(numbers:List<Int?>){
var sumOfValidNumbers = 0
var invalidNumbers = 0
for (number in numbers){ //从列表中读取可空值
if (number != null){ //检查值是否为null
sumOfValidNumbers +=number
}else {
invalidNumbers++
}
}
println("Sum of valid numbers: $sumOfValidNumbers")
println("Invalid numbers: $invalidNumbers")
}
>>> val reader = BufferedReader(StringReader("1\nabc\n42"))
>>> val numbers = readNumber(reader)
>>> addValidNumbers(numbers)
Sum of valid numbers: 43
Invalid numbers:1当你访问一个列表中的元素时,你得到的是一个类型为Int?的值,并且要在用它进行算数运算之前检查它是否为null。
Kotlin 提供了标准库函数filterNotNull函数,用来遍历一个包含可空值的集合并过滤掉null的操作。
fun addValidNumbers(numbers:List<Int?>){
val validNumbers = numbers.filterNotNull()
println("Sum of valid numbers:${validNumbers.sum()}")
println("Invalid numbers:${numbers.size - validNUmbers.size}")
}过滤影响了集合的类型。validNumbers的类型是List
6.3.2 只读集合与可变集合
集合分为两种:只读集合和可变集合
Kotlin 的集合设计和Java不同的另一个重要特质是,它把访问集合数据的接口和修改集合数据的接口分开了。这种区别存在于最基础的使用集合之中:kotlin.collection.Collection。使用这个接口,可以遍历集合中的元素、获得集合的大小、判断集合中是否包含某个元素,以及执行其他从集合中读取数据的操作。但这个接口没有任何添加或移除元素的返回。
使用kotlin.collection.MutableCollection接口可以修改接口中的数据。它继承了普通的kotlin.collections.Collection接口,并提供了方法来添加和移除、清空集合等。

通常规则是在代码的任何地方都应该使用只读接口,只在代码需要修改集合的地方使用可变接口的变体。
就像 val 和 var 之间的分离一样,只读集合接口和可变集合接口的分离能让程序中的数据发生的事情更容易理解。如果函数接收Collection而不是MutableCollection作为形参,你就知道它不会修改集合,而只是读取集合中的数据。如果函数要求你传递给它MutableCollection,可以认为它将会修改数据。如果你使用了集合作为组件部状态的一部分,可能需要把集合先拷贝一份传递给这个函数(这种模式通常称为 防御式拷贝)。
/* 使用只读集合接口与可变集合接口 */
fun <T> copyElemets(source: Collection<T>,
target: MutableCollection<T>){
for (item in source){ // 在source集合中的所有元素中循环
target.add(item) // 向可变的target集合中添加元素
}
}
>>> val source:Collection<Int> = arrayListOf(3,5,7)
>>> val target:MutableCollection<Int> = arratListOf(1)
>>> copyElements(source,target)
>>> println(target)
[1,3,5,7]只读集合类型不能作为可变集合的参数。不能把只读集合类型的变量作为target参数传给函数,即便它的值是一个可变集合:
>>> val source:Collection<Int> = arrayListOf(3,5,7)
>>> val target:Collection<Int> = arratListOf(1)
>>> copyElements(source,target)
Error: Type mismatch:inferred type is Collection<Int>
but MutableCollection<Int> was expected使用集合接口时需要牢记的关键点是 只读集合是不一定可变的。如果你使用的变量只有一个只读接口类型,它可能只是同一个集合的众多引用中的一个。任何其他的引用都可能拥有一个可变接口类型。

如果你调用了这样的代码,它持有其他指向你集合的引用,或者并行的运行了这样的代码。你依然会遇到这种状况,你正在使用集合的时候它被其他代码修改了,则会导致concurrentModificationException错误和其他一些问题。因此,必须了解只读集合并不总是线程安全的。如果你在多线程环境下处理数据,你需要保证代码正确的同步的对数据的访问,或者使用支持并发访问的数据结构。
6.3.3 Kotlin集合和Java
Kotlin接口是Java接口的实例。每一个Kotlin接口都是其对应Java集合接口的一个实例。在Kotlin和Java之间转移并不需要转换;不需要包装器也不需要拷贝数据。但每个Kotlin中都有两种表示:一种是只读一种是可变的。
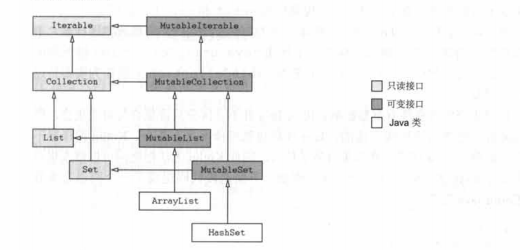
Kotlin中只读接口和可变接口的基本构造与 Java.util中的Java集合接口的构造是平行的。可变接口直接对应java.util中的接口,而它们的只读版本缺少了所有产生改变的方法。
Kotlin中Map类(并没有继承Collection或是Interable)也被表示成了两种不同的版本:Map和MutableMap。表中展示了不同集合的函数。
| 集合类型 | 只读 | 可变 |
|---|---|---|
| List | listOf | mutableListOf、arrayListOf |
| Set | setOf | mutableSet、hashSetOf、linkedSetOf、sortedSetOf |
| Map | mapOf | mutableMapOf、hashMapOf、linkedMapOf、sortedMapOf |
注意,setOf()和mapOf()返回的是Java标准库中类的实例(至少在Kotlin1.0版本中是这样),在底层它们都是可变的。但你不能完全信赖这一点:Kotlin的未来版本可能会使用真正不可变的实现类作为setOf和mapOf的返回值。
Set集合
在set集合中只包含不相同元素,也就是说相同类型会被移除。
elementAt函数
fun main() { val set = setOf<String>("one", "two", "3", "3") println(set.elementAt(1)) println() println(set.elementAt(4)) }描述
返回给定index处的元素,如果超出边界抛出 :[IndexOutOfBoundsException] 异常。

集合之间的快速转换
toSet()函数转换到Set集合类型
fun main() { var list = listOf<String>("one", "two", "3", "3") println(list) // 转换到toSet去除重复元素 val set = list.toSet() println(set) // 转换到List类型 list = set.toList() println(list) // 使用distinct去除重复元素 list += "3" println(list.distinct()) }

Map集合
获取Map集合的值,getOrDefault函数
按照键值对获取值,在值为null时返回参数 defaultValue中的值
fun main() { // 创建集合键值对喂String与Int类型 val map = mapOf<String, Int>(Pair("one", 1), Pair("two", 2)) // 获取键为 “one” 的值 println(map["one"]) // 使用 getOrDefault获取值 ,没有找到键值会返回 defaultValue = 0 val defaultValue = map.getOrDefault("two", 0) println(defaultValue) }
遍历Map集合
fun main() { val map = mapOf<String, Int>(Pair("one", 1), Pair("two", 2), "three" to 3) // 通过forEach获取遍历键和值,使用匿名函数获取 map.forEach { print("${it.key} ${it.value} \n") } println("--------------") // 通过for获取每个元素 ,key表示元素 for (key in map) { print("${key.key} ${key.value} \n") } }
可变Map添加元素
fun main() { val map = mutableMapOf<String, Int>(Pair("Li", 10), Pair("Liu", 20), "Wang" to 23) map += "Song" to 12 map += Pair("Zhou", 15) map["Tian"] = 16 // put函数在添加完成后如果key存在返回替换前的值,不存在返回null println(map.put("Zhou", 18)) println(map) }put函数
按照key与参数value进行关联,在添加时如果存在就返回之前的值并添加新值。



当你需要调用Java方法并把集合作为参数时。例如:使用java.util.Collection做为形参,你可以使用Collection或MutableCollection(只读集合或可变集合)的值作为实参传递给形参。
这时的操作对可变性有重要影响。因为Java并不会区分只读集合与可变集合,即使Kotlin中把集合声明成只读的,Java代码也可以修改这个集合。Kotlin编译器不能完全的分析Java代码到底对集合做了什么,因此Kotlin无法拒绝向可以修改集合的Java代码传递只读Colleciton。例如,如下代码组成了一个多语言兼容的Kotlin/Java程序:
/* Java */
// ColletionUtils.Java
public class ColletionUtils{
public static List<String> uppercaseAll(List<String> items){
for(int i = 0 ;i < items.size(); i++){
items.set(i,items.get(i).toUpperCase());
}
return items
}
}/* Kotlin */
// collections.kt
fun printInUppercase(list:List<String>){ // 声明只读的参数
println(CollectionUtils.uppercaseAll(list)) //调用可以修改集合的Java函数
println(list.first()) //打印被修改过的集合
}
>>> val list = listOf("a","b","c")
>>> printInUpppercase(list)
[A,B,C]
A如果你写了Kotlin函数,使用集合并传递给了Java,这时你要确认使用了正确的参数类型,同时取决于你调用的Java代码是否会修改集合。
注意,这些也适用于包含非空类型元素的集合类。如果你向Java方法传递了这样的集合,该方法就可能在其中写入null值;Kotlin没有办法再不影响性能的情况下,禁止它的发生,或者察觉到已经发生的改变。因此,当你向可以修改集合的Java代码传递集合的时,你需要采取特别的预防措施,来确保Kotlin类型正确的反映出集合上所有可能的修改。
6.3.4 作为平台类型的集合
Kotlin集合作为平台类型的集合
平台类型不会理会可空或者非空,所以在Kotlin重写或实现平台类型时需要选择集合是否可空。
Kotlin 把定义在java代码中的类型看成平台类型。Kotlin没有任何关于平台类型的可空性信息,所以编译器允许Kotlin代码将其视为可空或者非空的。同样,Java中声明的集合类型的变量也被视为平台类型。一个平台类型集合本质上就是可变性未知的集合——Kotlin代码将其视为只读的或者可变的。实际上你想要执行的所有操作都不受影响。
当你重写或者实现签名中有集合类型的Java方法时这种差异才变的重要。这里像平台类型的可空性一样,你需要决定使用那种 Kotlin类型 *来表示这个Java类型, *它来自你要重写或实现的方法。
在重写或者实现时,你要做出多种选择,它们都会反映在产生的Kotlin代码类型中:
- 集合是否可空?
- 集合的元素是否可空?
- 你的方法会不会修改集合?
代码中直观的表示。一个Java接口表示一个能处理文件中的文本对象。
/* 使用集合参数的Java接口 */
interface FileContentProcessor{
void processContents(File path,
byte[] binaryContents,
List<String> textContents);
}这个接口的Kotlin实现需要做出如下选择:
- 列表将是可空的,因为有些文件是二进制格式,它们的内容不能被表示成文本。
- 列表中的元素将会是非空的,因为文件中每一行都永远不为null。
- 列表将是可读的,因为它表示的文本内容,而且这些内容不会被修改。
实现的样子
/* FileContentProcessor 的Kotlin实现 */
class FileIndexer:FileContentProcessor{
override fun processContents(path:File,
binaryContents:ByteArray?,
textContents:List<String>?){
....
}
}与另一个接口对比。这里接口的实现从文本表单中解析出的数据并放大一个对象列表中,再把这些对象附加到输出列表中。当发现解析失败时,就把错误信息添加到另一个单独的列表中,作为错误日志。
/* 另一个集合参数的Java接口 Java*/
interface DataParser<T>{
void parseData(String input,
List<T> output,
List<String> errors);
}这种情况下的选择:
- List
将是非空的,因为调用者总是需要接收错误的信息。 - 列表的元素将是可空的,因为不是每个输出列表中的条目都有关联的错误信息。
- List
将是可变的,因为代码实现需要向其中添加元素。
实现这个接口
/* DataParser的Kotlin实现 */
class PersonParser: DataParser<Person>{
override fun parseData(input:String,
output:MutableList<Person>,
error:MutableList<String?>){
//...
}
}注意,同样为Java类型——List
6.3.5 对象和基本数据类型的数组
默认情况下,你应该优先使用集合而不是数组。但是因为有大量JavaAPI仍然在使用数组,所以来介绍它们在Kotlin中如何使用。
Kotlin 数组的语法出现在了每个例子中, 因为数组是 Java main 函数标准签名的一部分。
方法签名:
方法签名由方法名+形参列表组成,目的是让此方法确定为唯一的。
/* 使用数组 */
fun main(args:Array[String]){
for (i in args.indices){ // 使扩展属性array.indeces在下标的访问内迭代
pritnl("Argument $i is :${args[i]}") //通过下标使用 array[index] 访问元素
}
}Kotlin中的数组是一个带有类型参数的类,其元素类型被指定为相应的类型参数。
要在Kotlin中创建数组,如下方法供你选择
- arrayOf函数创建数组,它包含元素是指定为该函数的实参。
- arrayOfNulls创建一个给定大小的数组,包含为null元素。当然,它只能用来创建包含元素类型的可空数组。
- Array构造方法接收数组大小和一个lambda表达式,使用lambda表达式来创建每一个数组元素。这就是使用元素类型来初始化数组,当不用显式地传递每个元素的方式。
展示如何使用Array函数来创建“a”到”z”的字符串数组。
/* 创建字符数组 */
>>> val letters = Array<String>(26){i->('a'+i).toString()}
>>> pritnln(letters.joinToString(""))
abcdefghijklmnoprstuvwxyz为了清楚起见,这里显示了数组元素的类型,但在真实的代码中可以省略。因为编译器会推导出它的类型。
Kotlin 代码中最常见的创建数组的情况之一是需要调用参数为数组的Java方法,或是在调用带有vararg参数的Kotlin函数时。这种情况下,通常已经将数据存储在集合中,只需要将其转换为数组即可。可以使用toTypedArray方法来执行此操作。
/* 向vararg方法传递集合 */ >>> val string = listOf("a","b","c") >>> pritnln("%s/%s/%s".format(*strings.toTypedArray())) // 期望vararg参数时使用展开运算符(*)传递数组 a/b/c
数组类型的类型参数始终会变成对象类型。因此,如果你声明了一个Array
,它将会是一个包含装箱整型的数组(它的Java类型将是java.lang.Integer[])。如果你需要创建没有装箱的基本数据类型的数组,必须使用一个基本数据类型数组的特殊类。
为表示基本数据类型的数组,Kotlin提供了若干独立的类,每一个基本数据类型都对应一个。例如,Int类型值的数组叫做IntArray。
要创建一个基本数据类型的数组,你有如下选择:
- 该类型的构造方法接收size参数并返回一个使用对应基本数据类型默认值(通常是0)初始化好滴数组。
- 工厂函数(IntArray的intArrayOf,以及其他数组类型的函数)接收边长参数的值并创建存储这些的数组。
- 另一个构造方法,接受一个大小和一个用来初始化元素的lambda
例子
/* 下面创建存储了5个0的整形数组的两种选择 */
>>> val fiveZeros = IntArray(5) //默认值 0
>>> val fiveZerosToo = intArrayOf(0,0,0,0,0)/* 下面接收lambda的构造方法的例子 */
>>> val squares = IntArray(5){i->(i+1)*(i+1)}
>>> println(squares.joinToString())
1,4,9,16,25假如你有一个持有基本数据类型装箱后的值的数组或者集合,可以使用对应的转换函数把它们转换成基本数据类型的数组,例如toIntArray。
我们来看看你可是对数组做的事情。处理基本操作外(获得数组长度,获取或者设置元素),Kotlin标准库支持一套和集合相同的用于数组的扩展函数。其中(filter,map等)也适用于数组,包括基本数据类型的数组(注意这些返回值返回的是列表不是数组)。
/* 使用forEachIndexed函数加上lambda来重写”使用数组“例子 */ fun main(args:Array<String>){ atgs.forEachIndexed{index,elemnt -> println("Argument $index is: $element")} }
6.4 小结
- Kotlin对空类型的支持,可以帮助我们在编译期,检测出潜在的NullPointerException错误。
- Kotlin提供了安全调用(?.)、Elvis运算符(?:)、非空断言(!!)及let函数这些工具来简洁的处理可空类型。
- as?运算符提供了一个简单的方式来把值转换成一个类型,以及处理当它拥有不同类型时的情况。
- Java中的类型在Kotlin中被解释成平台类型,允许开发者把它们当作可空或非空来对待。
- 表示基本数据类型(如Int)看起来用起来都像普通的类,但通常会被编译成Java基本数据类型。
- 可空的基本数据类型(如Int?)对应着Java中的装箱基本数据类型(如java.lang.Integer)。
- Any类型是所有其他类型的超类型,类似于Java的Object。而Unit类比于void。
- 不会正常终止的函数使用Nothing类型作为返回类型。
- Kotlin使用标准Java集合类,并通过区分只读和可变集合来增强它们。
- 当你在Kotlin中继承Java类或者实现Java接口时,你需要自己考虑参数的可空性和可变性。
- Kotlin的Array类就像普通的泛型,但它会被编译成Java数组。
- 基本数据类型的数组使用像IntArray这样的特殊类来表示。
7 运算符重载及其他约定
- 运算符重载
- 约定:支持各种运算的特殊命名函数
- 委托属性
8 高阶函数:Lambda作为形参和返回值
内联函数作用
能够消除lambda带来的性能开销,还能够使lambda内的控制流更加灵活。
8.1 声明高阶函数
定义
高阶函数就是以另一个函数作为参数或者返回值的函数。在kotlin中,函数可以用lambda或者函数引用来表示。因此,任何以lambda或者函数引用作为参数的函数,或者返回值为lambda或函数引用的函数,或者两者都有满足的函数都是高阶函数。
标准库中的filter函数将一个判断式函数作为参数,因此它是一个高阶函数:
list.filter{x>0}8.1.1 函数类型
在变量中我们有Int类型,String类型等那么也有属于函数的函数类型。
声明一个lambda作为实参的函数,你需要知道如何声明对应形参的类型。在那之前,看接下来的例子,把 lambda 表达式保存在局部变量中。在不声明类型的情况下,这些就依赖于Kotlin的类型推导。
val sum = {x:Int,y:Int -> x+y}
val action = {println(42)}编译器推导出sum和action两个变量具有函数类型。
显式声明函数类型的变量
val sum:(Int ,Int) -> Int = {x,y->x+y} // 有两个Int类型参数和Int类型返回值
val action:() - > Unit = { println(42) } //没有参数和返回值声明函数类型,需要将函数参数类型放在括号中,紧接着是一个箭头和函数的返回值类型。
(Int,String) -> Unit
// ↑参数类型 ↑返回类型在声明函数类型时Unit是不能省略的,其他情况下可以。
函数类型的返回值标记为可空类型:
val canReturnNull: (Int,Int) -> Int?={null}定义函数类型的可空变量。
为了明确表示是变量本身可空,而不是函数类型的返回类型可空,你需要将整个函数类型的定义包含在括号内并在括号后添加问号。
val funOrNull:((Int,Int) -> Int) ?= null
8.1.2 调用作为参数的函数
实现一个高阶函数。
实现2,3两个数字的任意操作。
函数类型作为参数,形参和实参更像是接口,形参是接口实参则用来具体的实现。
定义一个简单的高阶函数
// 定义一个函数类型的参数
fun twoAndThree(operation: (Int,Int) -> Int){
val result = opration(2,3) // 调用参数(函数类型)
println("The result is $result")
}
>>> twoAndThree{a,b -> a+b}
The result is 5
>>> twoAndThree(a,b -> a*b)
The result is 6实现最常用的标准库函数:filter函数。为了更让事情更简单一些,将实现基于String类型的filter函数,但和作用于泛型的版本原理是显示的。
/* "String":接收者类型。
“predicate”:参数类型
“(Char) -> Boolean”:函数类型参数
“Char”:函数类型参数的参数类型
“Boolean”:函数类型的参数返回类型
*/
fun String.filter(predicate:(Char) -> Boolean):Stringfilter 函数的声明,以一个判断式作为参数
判断式的类型是一个函数,以字符作为参数并返回boolean类型的值。如果要让传递给判断式的字符出现在最终返回的字符串中,判断式需要返回ture,反之false。
// 实现一个简单版本的filer函数
fun String.filter(predicate: (Char) -> Boolean):String{
val sb = StringBuilder()
for (index in 0 until length){
val element = get(index)
if (predicate(element)) sb.append(element) // 调用引用的String类型参数给predicate函数进行判断
}
return sb.toString()
}
>>> println("ab1c".filter{it in 'a'..'z'}) //传递 lambda 作为 'predicate'参数
abcfilter 函数的实现非常简单明了。它检查每个字符时候满足判断式,如果满足就将字符添加到包含结果的StringBuilder中。
访问时作为参数的函数
reposeResult作为参数在编写时调用,在其它地方实现。
fun main() { loginAPI("TestFun", "12354") { msg, code -> println("登录 msg :$msg, code:$code") } loginAPI("TestFun213", "12354") { msg, code -> println("登录 msg :$msg, code:$code") } } const val USER_NAME_SAVE_DB = "TestFun" const val USER_PWD_SAVE_DB = "12354" fun loginAPI(username: String, userpwd: String, responseResult: (String, Int) -> Unit) { if (username == null || userpwd == null) { TODO("出现问题停止运行") } if (username.length > 3 && userpwd.length > 3) { if (webServiceLoginAPI(username, userpwd)) { // 登陆成功 responseResult("login sourcess", 200) } else { // 登陆失败 responseResult("login error", 400) } } else { TODO("“不合格 出现问题 ") } } private fun webServiceLoginAPI(name: String, pwd: String): Boolean { return name == USER_NAME_SAVE_DB && pwd == USER_PWD_SAVE_DB }

8.1.3 在Java中使用函数类
原理
函数类型被声明为普通的接口:一个函数类型的变量是FunctionN接口的实现。
Kotlin 标准库定义了一系列的接口,这些接口对应于不同的参数数量的函数:Function0
(没有参数的函数)、Function<P1,R>(一个参数的函数) 。每个接口定义了一个 invoke 方法,调用这个方法就会执行函数。
一个函数类型的变量就是实现了对应的Function接口的实现类的实力,实现类的invoke方法包含了lambda函数体。
在 Java 中调用使用了函数类型的 Kotlin 函数。
/* kotlin声明 */
fun processTheAnswer(f:(Int) ->){
println(f(42))
}/* Java */
>>> processTheAnswe(number -> number+1);
43在旧版 Java 中,可以传递一个实现了函数接口中 invoke 方法的匿名类的实例:
/* Java */
>>> processTheAnswer(
... new Function1<Integer,Integer>(){ // 在Java 8 以前使用函数类型
... @Override
... public Integer invoke(Integer number){
... System.out.println(number);
... return number+1;
... }
... });
43在 Java 中使用函数类型必须显示地传递一个接收者对象作为第一个参数。
在Java中可以很容易地使用 Kotlin 标准库中以lambda作为参数的扩展函数。
/* Java */
>>> List<String> strings = new ArrayList();
>>> strings.add("42")
>>> CollectionKt.forEach(strings, s ->{ //可以在Java中使用Kotlin标准库中的函数
... System.out.println(a);
... return unit.INSTANCE; // 必须显示的返回一个Unit类型的值。
...})在 Java 中 ,函数或许lambda可以返回Unit。因为在 Kotlin 中 Unit 类型是有值的,所以需要显示的返回它。
一个返回 void 的lambda 不能作为返回 Unit 的函数类型的实参,就像之前的例子中的(String) ->Unit.
8.1.4 函数类型的参数默认值和null值
声明函数类型的参数时可以指定参数的默认值。
用来理解参数默认值的关键作用
/* 使用了硬编码toString转换的joinToString函数 */
fun <T> Collection<T>.joinToString(
separator: String = ",",
prefix: String = "",
postfix: String = ""
): String{
val result = StringBuilder(prefix)
for ((index,element) in this.withIndex()){
if(index >0) result.append(separator)
result.append(element) // 使用默认toString方法将对象转换成字符串
}
result.append(postfix)
return result.toString()
}这里的实现很灵活但是并没有让你控制转换的关键点: 集合中的原始是如何转换成字符串的。
这里使用 StringBuilder.append(o:Any?) (result.append(element)),他总是使用toString方法将对象转换成字符串。在大多数情况下这样是可以的,但是不总是这样。
现在可以传递一个lambda去指定如何将对象转换成字符串。
但是要求所有调用者都传递lambda是比较烦人的,因为大部分调用者使用默认的行为就可以了。为了解决这个问题,可以定义一个函数类型的参数并用一个lambda作为它的默认值。
/* 给函数类型的参数指定默认值 */
fun <T> Collection<T>.joinToString(
separator: String = ",",
prefix: String = "",
postfix: String = "",
transform: (T) -> String = {it.toString()} //声明一个lambda为默认值的函数类型的参数
): String {
val result = StringBuilder(prefix)
for ((index,element) in this.withIndex()){
if(index > 0 ) result.append(separator)
result.append(transform(element)) // 调用作为实参的element传递给 “transform”形参的函数
}
result.append(postfix)
return result.toString()
}
>>> val letters = listOf("Alpha","Beta")
>>> println(letters.joinToString()) // 使用默认的转换函数
Alpha, Beta
>>> println(letters.joinToString{it.toLowerCase()}) // 传递一个 lambda 作为参数
alpha,beta
>>> println(letters.joinToString(separator = "!",postifx = "!", transform = {it.ToUpperCase()})) // 使用命名参数参数语法几个参数,包括lambda。
ALPHA,BETA这个带默认值的函数类型是一个泛型参数T表示集合中的元素类型。 Lambda transform 将接收这个类型的参数。
声明函数类型的默认值并不需要特殊的语法,只需要把 lambda 作为值放在 = 号后。上述例子展示了多种方式调用函数类型。
声明函数类型其参数是可空的
/* 案例1 一般情况*/
fun foo(callback: (() ->Unit)?){
if(callback != null){
callback()
}
}
这里不能直接调用作为参数传递进行的函数:Kotlin 会因为检查到潜在的空指针异常而导致编译失败。这里可选的办法是显式地检查null。
/* 使用函数类型的可空参数 */
fun <T> Collection<T>.joinToString(
separator: String = ",",
prefix: String = "",
postfix: String = "",
transform: ((T) -> String ) ?=null // 声明一个函数类型的可空参数
): String{
val result = StringBuilder(prefix)
for ((index,element) in this.withIndex()){
if (index > 0) result.append(separator)
val str = transform?.invoke(element) // 使用安全调用语法,调用函数
?: element.toString() //使用 Elvis 运算符处理回调没有被指定的情况
result.append(str)
}
result.append(postfix)
return result.toString()
}这是一个更简单的版本,它利用了一个事实 ,函数类型是包含 invoke 方法的接口具体实现。作为一个普通方法,invoke可以通过安全调用语法被调用:callback?.invoke()方法
8.1.5 返回函数的函数
/* 定义一个返回函数的函数 */
enum class Delivery {STANDARD, EXPEDITED}
class Order(val itemCount:Int)
fun getShippingCostCalculator(delivery:Delivery):(Order)->Double{ // 声明返回函数的函数
if (delivery == Delivery.EXPEDITEM){ // 返回 lambda
return {order -> 6+2.1 * order.itemCount}
}
return {order ->1.2*order.itemCount}
}
>>> val calculator = getShippingCostCalculator(Delivery.EXPEDITEM) // 将返回的函数保存在变量中
>>> println("Shapping costs ${calculator(Order(3))}") // 调用返回的函数
Shipping costs 12.3使用场景
例如,运输费用的计算依赖于选择恰当的逻辑变体并将它作为另一个函数返回。声明一个 返回另一个函数的函数,需要指定一个函数类型作为返回类型。
函数 getShippingCostCalculator返回一个函数,这个函数以Order最为参数并返回一个Double类型的值。
要返回一个函数,需要写一个return表达式,跟上一个lambda、一个成员引用,或者其他的函数类型的表达式,比如一个函数的局部变量。
返回函数的函数通过。打印字符穿的长度。
returnFun返回一个获得字符长度的函数并在applyFun中调用它获得长度并打印它的长度。
fun main() { applyFun("testReturnFunLength") } fun applyFun(testName: String) { val testReturnFun = returnFun() println("$testName, 字符串的函数${testReturnFun(testName)}") } fun returnFun(): (testName: String) -> Int { return { testName -> testName.length } }

另一个返回函数的例子
例如,你可以在 UI 上输入一个字符串,然后只显示那些名字以这个字符串开头的联系人;还可以隐藏没有电话号码的联系人。用ContactListFilters这个类来保存这个选项的状态。
class ContactListFilters{
var prefix: String = ""
var onlyWithPhoneNumber: Boolean = false
}当用户输入 D 来查看姓或者名以 D 开头的联系人时,prefix的值会被更新。
/* 在UI代码中定义一个返回函数的函数 */
data class Persion(
val firstName:String,
val lastName:String,
val phoneNumber:String?
)
class ContactListFilters{
val prefix:String = ""
val onlyWithPhoneNumber: Boolean = false
fun getPredicate():(Person) -> Boolean{ //声明一个返回函数的函数
val startWithPrefix = {p:Persion -> p.firstName.startsWith(prefix) || p.lastName.startsWith(prefix)
}
if (!onlyWithPhoneNumber){
return startWithPrefix // 返回一个函数类型的变量
}
return { startsWithPrefix(it)&&it.phoneNumber != null } //从函数返回一个lambda
}
}
>>> val contacts = listOf(Persion("Dmitry","Jemeroy","123-4567"),
... Persion("Svetlane","Isakova",null))
>>> val contactListFilters = ContactListFilters()
>>> with (contactListFilters){
>>> prefix = "Dm"
>>> onlyWithPhoneNumber = true
>>> }
>>> println(contacts.filter(
... contactListFilters.getPredicate())) // 将 getPredicate 返回的函数作为参数传递给 “filter” 函数
[Persion (firstName = Dmitry,lastName = Jemetov,phoneNumber = 123-4567)]为了让展示联系人列表的逻辑代码和输入的过滤条件的UI条件解耦,可以定义一个函数来创建一个判断式,用来过滤联系人列表。判断式检查前戳,如果有需要也检查电话号码时候存在。
getPredicate 函数返回一个函数(类型)的值,这个值被传递给filter作为参数。
8.1.6 通过lambda 去除重复代码
例子
这是一个分析网站访问的例子。SiteVisit类用来保存每次访问的路径、持续时间和用户的操作系统。不同的操作系统使用枚举来表示。
/* 定义站点访问数据 */
data calss SiteVisit(
val path: String,
val dutation: Double,
val os: OS
)
enum class OS{ WINDOWS,LINUX,MAC,IOS,ANDROID}
val log = listOf(
SiteVisit("/",34.0,OS.WINDOWS),
SiteVisit("/",22.0,OS.MAC),
SiteVisit("/login",12.0,OS.WINDOWS),
SiteVisit("/signup",8.0,OS.IOS),
SiteVisit("/",16.3.OS.ANDROID)
)需要显示来自 Windows 的平均访问时间,可以使用 average 函数来完成这个任务。
/* 使用硬编码的过滤器分析站点访问数据 */
val averageWindowsDutation = log
.filter {it.os == OS.WINDOWS}
.map(SiteVisit::dutation)
.avaerage()
>>>println(averageWindowsDutaion)
23.0显示来自于Windows机器的平均访问时间,用 average 函数来完成任务。
/* 使用普通的方法去除重复代码 */
fun List<SiteVisit>.averageDurationFor(os:OS) = filter{it.os == os}.map(SiteVisit::dutation).average() // 将重复代码抽取到函数中
>>> println(log.averageDurationFor(OS.WINDOWS))
23.0
>>> println(log.averageDurationFor(OS.MAC))
22.0现在你要计算一个来自MAC用户的相同数据,为了避免重复,可以将平台类型抽象成一个参数.
注意这个函数作为扩展函数增强了可读性。如果它值在局部的上下文中有用,你甚至可以将这个函数声明为局部的扩展函数。
/* 用一个重复的硬编码函数分析站点访问数据 */
val averageMobileDutation = log
.filter{it.os == setOf(OS.IOS,OS.ANDROID)}
.map(SiteVisit::duration)
.average()
>>> println(averageMobileDuration)
12.15
如果你对移动平台的访问的平均时间感兴趣。
这时已经不能再再用简单的参数表示不同的平台了。可能还需要使用更加复杂的条件查询日志,比如,“来自IOS平台对注册页面的访问平均时间是多少?”
可以使用函数类型将需要的条件抽象到一个参数中
/* 用高阶函数去除重复代码 */
fun List<SiteVisit>.averageDutationFor(predicate:(SiteVisit) -> Boolean) = filter(predicate).map(SiteVisit::duration).average()
>>> println(log.averageDurationFor{
... it.os in setOf(OS.ANDROID,OS.IOS)
})
12.15
>>> println(log.averageDurationFor{
... it.os == OS.IOS && it.path == "/signup" // 满足系统为IOS,访问地址为 注册界面的条件
})
8.0函数类型可以帮助去除重复代码。使用lambda,不仅可以去除重复的数据,也可以去除重复的行为。
8.2 内联函数:消除lambda带来的运行时开销
Kotlin 中传递 lambda 作为函数参数的简明语法与普通的表达式语法很相似。
lambda 表达式会被正常地编译成匿名类。这表示每调用一次 lambda 表达式,就会额外的创建一个类。并且如果 lambda 捕捉了某个变量,那么每次调用的时候都会创建一个新的对象。这会带来运行时的额外开销,导致使用 lambda 比使用一个直接执行相同代码的函数效率更低。
有没有可能让编译器生成跟 Java 语句相同高效的代码,但还是能把重复的逻辑抽取到库函数中呢?(作用)
如果使用 inline 修饰符标记一个函数,在函数被使用的时候编译器并不会生成函数调用的代码,而是使用函数实现的真实代码替换每一次的函数调用。
内联函数简介
在计算机科学中,内联函数(有时称作在线函数或编译时期展开函数)是一种编程语言结构,用来建议编译器对一些特殊函数进行内联扩展(有时称作在线扩展);也就是说建议编译器将指定的函数体插入并取代每一处调用该函数的地方(上下文),从而节省了每次调用函数带来的额外时间开支。但在选择使用内联函数时,必须在程序占用空间和程序执行效率之间进行权衡,因为过多的比较复杂的函数进行内联扩展将带来很大的存储资源开支。另外还需要特别注意的是对递归函数的内联扩展可能引起部分编译器的无穷编译。
8.2.1 内联函数如何运作
内联函数!
当一个函数被声明为 inline 时,它的函数体是内联的–换句话说,函数体会被直接替换到函数被调用的地方,而不是被正常调用。
/* 定义一个内联函数 */
inline fun <T> sysnchronized(lock:Lock,action : () -> T):T{
lock.lock()
try{
return action()
}
finally {
lock.unlock()
}
}
val l = Lock()
synchronized(1){
//...
}函数用于确保一个共享资源不会并发地被多个线程访问。函数锁住一个Lock对象,执行代码块。
调用这个函数的语法跟Java中使用 synchronized 语法完全一直。区别,Java 的 synchronized 语法可以用于任何对象,这个函数则要求传入一个Lock实例。
同时,Kotlin 标准库中定义了一个可以接受任何对象作为参数的 synchronized 函数版本。
这里使用同步操作时显式的对象锁能够提升代码的可读性和维护性。
使用 inline 的效果!
因为已经将 synchronized 函数声明为 inline,所以每次调用它所生成的代码跟 Java 的synchronized 语句都是一样的。
使用 synchronized 的例子。
fun foo(l:Lock){
println("Before sync")
synchronized(1){
println("Action") //内联函数
}
println("After sync")
}/* 编译后的 foo 函数 */
fun _foo_(l:Lock){
println("Before sync") //这是调用者 foo 的代码
l.lock() // 这是被内联的 synchronized 函数代码
try(
println("Action") //被内联的lmabda题代码
)finally{
l.unlock() //这是调用者 foo 的代码
}
println("After sync") //这是调用者 foo 的代码
}展示的是作用相同的代码,将会被编译成同样的字节码。
这里 lambda 表达式 和 synchronized 函数实现了内联。
由于lambda 生成的字节码成为了函数调用这定义的部分,而不是被包含在一个实现了函数接口的匿名类中
/* 调用内联函数的时候可以传递函数类型的变量作为参数 */
class LockOwner(val lock:Lock){
fun runUnderLock(body:() -> Unit){
synchronized(lock,body) //作为函数类型的变量作为参数,而不是lambda
}
}使用函数类型的变量作为参数,不会被内联。
只有synchronized 函数体被内联了,lambda 才会被正确调用。
/* runUnderLock 的函数字节码 */
class LockOwner(val lock:Lock){
fun runUnderLock(body:() -> Unit){ //函数类似于真正的runUnberLock被编译成的字节码
lock.lock()
try{
body() // body 没有被内联,因为在调用到地方换没有 lambda
}finally{
lock.unlock()
}
}
}8.2.2 内联函数的限制
鉴于内联的运作方式,不是所有使用lambda的函数都可以被内联的。
当函数被内联的时候,作为参数的lambda表达式函数体会被直接替换成最终生成的代码中。这会限制函数体中对应的(lambda)参数使用。如果(lambda)参数被调用,这样的代码能被容易的内联。但是如果(lambda)参数在某个地方被保存起来,一遍后边可以继续使用,lambda表达式的代码将不能被内联,因为必须要有一个包含这些代码的对象存在。
一般来说,参数如果被直接调用或者作为参数传递给另外一个inline函数,它是可以被内联的。否则,编译器会禁止参数被内联并给出错误信息“Illeal usage of inline-parameter”
例如,许多作用域序列的函数会返回一些类的实例,这些类代表对应的序列操作并接受lambda作为构造参数。 这是 Sequence.map函数的定义:
fun <T,R> Sequence<T>.map(transform:(T) -> R):Sequence<R>{
return TransformingSequence(this,transform)
}map 函数没有直接调用作为 transform参数传递进来的函数。而是将这个函数传递给类的构造方法,构造方法将它保存在一个属性中。
这时为了支持这一点,作为transform参数传递的lambda需要被编译成标准的非内联的表达式,即实现了一个函数接口的匿名类。
当函数期望两个或多个 lambda 参数,可以选择只内联其中一些参数。这是有道理的,因为一个lambda可能会包含很多代码或者不允许内联的方式使用。接受这样的非内联lambda的参数,可以用 noinline 修饰符来标记它:
inline fun foo(inlined:() -> Unit,noinlune notInlined:() -> Unit){ //... }
8.2.3 内联集合操作
Kotlin 标准库中操作集合函数的性能。大部分标准库中的集合函数都带有lambda参数。不管使用标准库函数,还是直接实现这些操作效率都是一样的。
我们来比较一下。
/* 使用lambda过滤一个集合 */
data class Person(val name:String,val age:Int)
val people = listOf(Persion("Alice",29),Person("Bob",31))
>>> println(people.filter(it.age<30))
[Person(name = Alice,age = 29)]/* 手动过滤一个集合 不用lambda表达式来实现*/
>>> val result = mutableListOf<Person>()
>>> for (person in people){
>>> if(person.age < 30) result.add(person)
>>>}
>>> println(result)
[Person(name = "Alice", age = 29)]Kotlin 对内联函数的支持让你不必担心性能问题。
在Kotlin中,filter 函数被声明为内联函数。这意味着 filter 函数,以及传递给它的lambda的字节码会被一起内联到filter被调用的地方。最终,第一种实现所产生的字节码和第二种实现所产生的字节码大致是一样的。你可以很安全地使用符合语言习惯的集合操作。
现象你在连续使用 filter 和 map 两个操作。
>>> println(people.filter{it.age > 30} ... .map (Persion::name)) [Bob]这个例子使用了 lambda 表达式和一个成员引用。
这里 filter 和 map 都被声明为了 inline 函数,所以他们的函数体会被内联,因此不会产生额外的类和对象。上述的代码却创建了一个中间集合来把偶出来列表过滤的结果,由 filter 函数生成的代码会向这个集合种添加元素,而由 map 函数生成的代码会读取这个几个。
如果有大量的元素需要处理,中间集合的运行开销将成为不可忽视的问题,这时可以在调用链后加上一个asSequence调用,用序列代替集合。
同时如同上一节看到的一样,用于处理序列的 lambda 不能够被内联,每个中间序列被表示成lambda保存在其字段中的对象,而末端操作会导致由每个中间序列调用组成的链被执行。因此,即便序列上的操作是惰性的,你不应该总是试图在集合操作的链后asSequence。只有在处理大量数据时有用,小的集合可以用普通集合处理。
8.2.4 决定何时将函数声明成内联
使用 inline 关键词只能提高 lambda 参数的函数性能,其他情况需要额外的度量和研究。
将带有 lambda 参数的函数内联能够带来什么好处。
首先, 通过内联避免运行时开销更加明显了。毕竟节约了函数运行时的开销,而且节约了 lambda 创建匿名类,以及创建 lambda 实例对象的开销。其次,JVM 还没有聪明到总是能将函数调用内联。内联可以使用一些不可能被普通 lambda 使用的特征,比如非局部返回。
注意
在使用 inline 关键字的时候,你还是应该注意代码的长度。如果你要内联的函数不大,将它的字节码拷贝到每一个调用点将会极大地增加字节码的长度。在这种情况下,你应该将那些与 lambda 参数无关的代码抽取到一个独立的非内联函数中。在 Kotlin 中内联函数总是很小的。
8.2.5 使用 内联 lambda 管理资源
Lambda 可以去除重复代码的一个常见模式是资源模式
先获取资源,完成一个操作,释放资源。
这里资源表示多种不同的东西:一个文件、一个锁、一个数据库事务等。
实现这个模式的标准做法是使用 try/finally 语句。资源在 try 代码块之前被获取,在 finally 代码块中释放。
synchronization
前部分讲到将 try/finally的逻辑封装在一个函数中,然后将使用资源的代码作为 lambda 传递给这个方法。
synchronization将一个锁对象作为参数。
代替 synchronization
Kotlin 标准库定义了一个叫 withLock的函数,它提供了实现同样功能的更符合语言习惯的API:它是 Lock 接口的扩展函数。
如何使用。
val l:Lock = ... l.withLock{ // access the resource protected by this lock 在加锁的情况下执行指定的操作。 } /* 在Kotlin标准库中的定义 */ fun <T> Lock.withLock(action : () -> T):T{ //需要加锁的代码被抽取到一个独立的方法中 lock() try{ return action() } finally{ unlock() } }
文件是另一种可以使用这种模式的常见资源类型。(文件使用 资源模式)
Java 7 为这种模式引入了特殊的语法:try-with-resource 语句。
/* 下述代码来读取文件的第一行Java方法 */ /* 在Java中使用try-with-resource语句 */ static String readFirstLineFromFile(String path) throws IOException{ try(BufferedReader br = new BufferedReader(new FileReader(path))){ return br.readLine(); } }Kotlin 中并没有等价的语法,因为通过使用一个带有函数类型参数的函数可以无缝地完成相同的事情。这个函数叫use()
使用 use 函数 重写上述代码
/* 使用use函数作为资源管理 */ fun readFirstLineFromFile (path:String):String{ BufferedReader(FileReader(path)).use{ // 构成 BufferedReader,调用 “use” 函数,传递一个lambda执行文件操作 br -> return br.readLine() // 从函数中返回文件的一行 } }use 函数是一个扩展函数,被用来操作可关闭的资源,它接受一个lambda作为参数。这个返回调用lambda并且确保资源被关闭,无论lambda正常执行饭是抛出了异常。当然使用use函数是内联函数,所以使用它并不会引发任何性能开销。
8.3 高阶函数中的控制流
把 return 语句放在循环的中间是很简单的事情,但是如果将循环转换成一个类似于 filter (filter 是内联函数) 的函数呢?这种情况下 return 会如何工作。
8.3.1 lambda 中的返回语句:从一个封闭的函数返回
比较两种不同的 遍历集合的返回: 在下面的代码清单中,如果一个人的名字是 “Alice” ,就应该从函数lookForAlice 返回。
/* 在一个普通循环中使用return */
data class Person(val neme:String, val age:Int)
val people = listOf(Person ("Alice",29),Person("Bob",11))
fun lookForAlice(people:List<Person>){
for (person in people){
if (person.name == "Alice"){
println("Found!")
return
}
}
println("Alice is not found") //如果“people”中没用Alice,这一行就会被打印出来
}
>>> lookForAlice(people)
Found!使用 forEach迭代重写这段代码安全吗?
/* 在传递给 forEach 的lambda 中使用 return */ fun lookForAlice(people:List<Person>){ people.forEach{ if (it.name == "Alice"){ println("Found!") return } } println("Alice is not found") //和上一个代码清单中的效果是一样的 }这是安全的
当你在 lambda 中使用 return 关键字,它会从调用 lambda 的函数中返回,并不是从 lambda 中返回。这个叫做非局部返回。因为它从一个比包含 return 的代码块更大的代码块中返回了。
为了理解这条规则背后的逻辑,从Java函数中在for循环或者synchronized 代码块中使用 return 关键字。显然这会从函数中返回,而不是从循环或者代码块中返回。使用以 lambda 作为参数的函数的时候 kotlin 保留了同样的行为。
需要注意的是,只有在以 lambda 作为参数的函数是内联函数的时候才能从跟外层的函数返回。在上述代码中,forEach 的函数体和lambda的函数体一起被内联了,所以在编译的时候能很容易做到从包含它的函数中返回。在 非内联函数的lambda 中使用 return 表达式是不允许的。一个非内联函数可以把传给它的lambda保存在变量中,以便在函数返回以后可以继续使用,这个时候lambda先去影响函数的返回已经太晚了。
8.3.2 从 lambda 返回:使用标签返回
标签返回
可以在lambda表达式总使用局部返回。
lambda 中的局部返回跟 for 循环中的 break 表达式显示。它会终止 lambda 的执行,并接着从调用 lambda 的代码处执行。
区分 局部返回和非局部返回
要区分局部返回和非局部返回,要用到标签。
如何区分。
想从 lambda 表达式处返回你可以标记它,然后在 return 关键字后面引用这个标签。
/* 用一个标签实现局部返回 */
fun lookForAlice(people:List<Person>){
people.forEach lable@{ // ←给lambda表达式加上标签
if (it.name == "Alice") return@label //← return@label 引用了这个标签
}
println("Alice might be somewhere") //这里总被打印
}
>>> lookForAlice(people)
Alice might be somewhere!如何使用标签
要标记一个lambda表达式,在 lambda 的花括号之前放一个标签名,接着放一个 @ 符号。(标签名可以是任意的)、
要从一个lambda返回,在return关键词后放一个@符号,接着放标签名。
// “label@” lambda标签 people.forEach label@{ if (it.name == "Alice") return@label //返回表达式标签 } /* 用 “@” 符号标记一个标签从一个lambda返回 */
另一种方式,使用 lambda 作为参数的函数的函数名可以作为标签
/* 用函数名 return 标签 */ fun lookForAlice(people:List<Person>) { people.forEach{ if(it.name == "Alice") return@forEach // ←return@forEach从 lambda 表达式返回 } println("Alice might be somewhere") }当里显式的指定了 lambda 表达式的标签,再使用函数名作为标签没有任何效果。
一个 lambda 表达式的标签数量不能多于一个。
带标签的 “this” 表达式
同样的规则也适用于this表达式。在带接收者的lambda中–包含一个隐式上下文对象的lamdba也有通过一个this去访问。
如果你给带接收者 lambda 指定标签,就可以通过对应的带有标签的this表达式访问它的隐式接收者。
>>> println(StringBuilder().apply sb@{ // 这个 lambda 隐式接收者可以通过 this@sb 访问 ... listOf(1,2,3).apply{ // ”this”指定作用域内最近的隐式接收者 ... this@sb.append(this.toString()) // 所以隐式接收者都可以被访问,外层的接收者通过显式的标签访问 ... } ... }) [1,2,3]局部返回的语法相当冗长,如果一个 lambda 包含多个返回语句会变得更加笨重。所以这里可以使用 匿名函数。
9 泛型
Kotlin中引入了新的概念,例如实化类型参数和声明点变型。
实化类型参数允许你在运行时的内联函数调用中引用作为类型实参的具体类型(对普通的类和函数来说,这样行不通,因为类型实参在运行时会被消除)
声明点变型可以说明一个带类型参数的泛型类型,是否是另一个泛型类型的之类或者超类型,它们的基础类型相同但类型参数不同。例如它可以调节是否可以把List
类型参数:
在计算机编程语言中,TypeParameter是用于泛型编程的通用标签,用于引用未知的数据类型,数据结构或类。TypeParameter最常用于C ++模板和Java泛型。TypeParameter与元语法变量相似,但有所不同。
引用:维基百科
9.1 泛型类型参数
泛型允许你定义带类型形参的类型。当这种类型的实例被创建出来的时候,类型形参被替换成称为类型实参的具体类型。
类型形参:声明定义时的参数,作用域仅本身。
Kotlin编译器能推导出类型实参:
val authors = listOf("Dmitry","Svetlane")因为传给listOf函数的两个值都是字符串,编译器推导出你正在创建一个List
val readers :MutableList<String> = mutableListOf()
val reader = mutableListOf<String>()9.1.1 泛型函数和属性
如果你在编写一个使用列表的函数,希望它可以在任何列表上使用,而不是某个具体类型的元素列表,那么编写一个 泛型函数。
泛型函数有它自己的类型形参。类型形参在每次函数调用时都必须替换成具体的类型实参。
大部分使用集合的库函数都是泛型的。下面这个函数就返回一个只包含在指定下标区间内的元素。
fun <T> List<T>.slice(indeces: IntRange):List<T> //接收者和返回类型使用了类型形参
// <T>:类型形参声明接收者和返回类型用到了函数的类型形参T,它们的类型都是List
多数情况下,编译器会推导出类型。
//调用泛型函数
>>> val letter = ('a'..'z').toList()
>>> println(letter.slice<Char>(0..2)) //显式地指定类型实参
[a, b, c]
>>> println(letter.slice<Char>(10..13))
[k, l, m, n]调用的结果都是List
9.1.2 声明泛型类
和Java一样,Kotlin通过在内名称后加上一对尖括号,并把类型参数放在尖括号内来声明泛型类及接口。
一旦声明以后,就可以在类的主体内像其他类型一样使用类型参数。
interface List<T>{ //List 接口顶类类型参数T
operator fun get(index:Int):T //在接口或类的内部,T可以当作普通类型使用。
}如果你的类继承了泛型类(或者实现了泛型接口),你就得为基础类型的泛型形参提供一个类型实参。它可以是具体类型或一个类型形参:
class StringList(override val size: Int) : List<String> { //这个类实现了List,提供了具体类型实参:String override fun get(index: Int): String { //注意T被String替代 TODO("Not yet implemented") } } class ArratList<T> : List<T> { // 现在ArrayList泛型类型形参T就是List的类型实参。 override fun get(index: Int): T { TODO("Not yet implemented") } }StringList类被声明成只能 只能包含String元素,所以它使用String作为基础类型的类型实参。之类中的任何函数都要用这个正确的类型换掉T,所以在StringList中你会得到函数签名get(Int):String ,而不是fun get(Int):T。
而类ArrayList定义了它自己的类型参数T并把它指定为父类的类型实参。注意ArrayList
中的T和LIst 中的T不一样,它是全新的类型形参,不必保留一样的名称。 一个类甚至可以把它自己作为类型实参应用。实现Comparable接口的类就是这种模式的经典例子。任何可以比较的元素都必须定义它如何与同样类型的对象进行比较:
interface Comparable<T> { fun comparableTo(other: T): Int } class String : Comparable<String> { override fun comparableTo(other: String): Int { TODO("Not yet implemented") } }String 实现了Comparable接口的泛型接口,提供类型String给类型实参T。
9.1.3 类型参数约束
类型参数约束可以限制作为类和函数的类型实参的类型。 以计算列表元素之和的函数为例。它们可以在List
和List 上,当不可以用在LIst 这样的列表上。可以定义一个类型参数的约束,说明sum的类型形参必须是数字,来表达这个限制。
如果你把一个类型指定为泛型类型形参的上街约束,在泛型类型具体的初始化中,其对应的类型实参就必须这个具体类型或它的子类型(暂时子类型和子类的一样相同)。
你是这样定义约束的,把冒号放到类型参数名称之后,作为类型形参上界的类型紧跟其后,在Java中,用的关键词extends来表达一样的概念:
T sum(List list)。 // <T: 类型参数 // Number> :上界 fun <T:Number> List<T>.sum():T
一旦指定了类型形参T的上界,你就可以把类型T的值作为它的上界(类型)的值使用。
fun <T : Number> oneHalf(value: T): Double { //指定Number为类型形参上界 return value.toDouble() / 2.0 } >>> println(oneHalf(3)) 1.5
// 声明带类型参数约束的函数 fun <T : Comparable<T>> max(first: T, second: T): T { //这个函数的实参必须是可比较元素 return if (first > second) first else second } >>> println(max("kotlin", "java")) // 字符串按照字母表顺序比较T的上界是泛型类型Comparable
。前面已经看到了,String累继承了Comparable 这样使得String变成了max函数的有效类型实参。 记住,first>second的简写形式会根据Kotlin的运算符约定被编译成first.compareTo(second) > 0。这种比较之所以可行,是因为first的类型T继承自Comparable
,这样你就可以比较first和另外一个类型T的元素。 极少数情况下,需要在类型参数上指定多个约束。例如下面这个代码清单用泛型的饭是保证给定的CharSequence以句号结尾。
//为一个类型参数指定多个约束 fun <T> ensureTrailingPeriod(seq: T) where T : CharSequence, T : Appendable { //类型参数约束的列表 if (!seq.endsWith(".")) { //调用为CharSequence接口定义的扩展函数 seq.append(".") //调用Appendable接口的方法 } } >>> val helloWorld = StringBuilder("Hello World") >>> ensureTrailingPeriod(helloWorld) >>> println(helloWorld)这种情况下,可以说明作为类型实参的类型必须实现CharSequence和Appendable接口。这意味着该类型的值可以使用访问数据(endsWith)和修改数据(append) 两种操作。
9.1.4 让类型形参非空
class Processor<T>{ fun process(value:T){ value?.hashCode() //“value“是可空的,所以要安全调用 } }如果你声明的是泛型类或者泛型函数,任何类型实参,包括哪些可空的类型实参,都可以替换它的类型形参。没有指定上界的类型形参将会使用Any?这个默认上界。
process函数中,参数value是可空的,尽管T并没有使用问好标记。下面这种情况是因为Processor类具体初始化T能使用可空类型。
val nullableStringProcessor = Processor<String?>() //可空类型替换为String?被用来替换T nullableStringProcessor.process(null) //使用“null”作为“value”实参的代码可以编译如果你想保证替换类型形参的始终是非空类型,可以通过指定一个约定来实现。如果你除啦可空性之外没有任何限制,可以使用Any代替默认的Any?作为上界:
class Processor<T:Any>{ //指定非空上界。 fun process(value:T){ value.hashCode() //类型T的值现在是非“空”的。 } }约束<T:Any>确保了类型T永远都是非空类型。编译器不会接收代码Processor<String?>,因为类型实参String?不是Any的子类型。(它是 Any? 的子类型)
可以通过指定任意非空类型作为上界,来让类型参数非空,不光是类型Any。
9.2 运行时的泛型:擦除和实例化参数
JVM上的泛型一般是通过类型擦除实现,就是说泛型类实例的类型实参在运行时是不保留的。可以声明一个inline函数,使其类型实参不被擦除(或者,Kotlin术语称为实化)。
9.2.1 运行时的泛型:类型检查和转换
和Java一样,Kotlin的泛型在运行时也被 擦除 了。这意味着泛型类实例不会携带用于创建它的类型实参的信息。例如,如果你创建了一个List
val list1:List<String> = listOf("a","b")
val list2:List<Int> = listOf(1,2,3)
即使编译器看到的是两种完全不同类型的列表,在执行的时候它们看起来却完全一样。即便如此,你通常可以确信List
因为类型实参没有被保留下来,你不能检查它们。例如,你不能判断一个列表是只包含字符串的列表还是包含其它对象的列表。一般而言,在is检查中不可能使用类型实参中的类型。
>>> if (value is List<String>){...}
ERROR:Cannot check for instance of erased type为什么擦除了泛型类型信息?
尽管在运行时可以完全断定这个值是一个List,但你依然无法判断它是一个含有字符串的列表,还是含有人,或者含有其他什么:这些信息被擦除了。注意擦除泛型类型信息是有好处的:应用程序使用的内存总量较小,因为要保存在内存中的类型信息更少。
检查类型是否是个列表?
路上所述,Kotlin不允许使用没有指定类型实参的泛型类型。那么你可能想知道如何检查一个值是否是列表,而不是set或者其他对象。可以使用特殊的星号投影语法来做这种检查:
if (value is List<*>){... ...}这里检查了value是否是一个List,而且并没有得到关于它的任何信息。
注意,在as 和 as? 转换中仍然可以使用一般的泛型类型。但如果该类有正确的基础类型但类型实参是错误的,转换也不会失败,因为在运行时转换发生的时候类型实参是未知的。因此这样的转换会导致编译器发出“unchecked cast”(未受检转换)的警告。这仅仅是个警告,你仍然可以继续使用这个值,但它拥有必要的类型。
// 对泛型类型做类型转换 fun printSum(c: Collection<*>) { val initList = c as? List<Int> ?: throw IllegalArgumentException("List is expected") //这里警告。Unchecked cast:List<*>to List<Int> println(initList.sum()) } >>> printSum(listOf(1, 2, 3)) 6编译一切正常:编译器只是发出了一个警告,这意味着代码是合法的。如果一个整型的列表或者set上调用printSum函数,一切都会如预期发生:一种情况会打印出元素之和,而第二种情况则会IllegalArgumentException。但如果你传递了一个错误类型的值,运行时会得到一个ClassCastException:
>>> printSum(setOf(1,2,3)) //Set不是列表所以抛出了异常 IllegalArgumentException:List is expected >>> printSum(listOf("a","b","c")) //类型转换成功,但后面抛出了另外的异常 ClassCastException:String cannot be cast to Number我们来讨论一下字符串列表上调用printSum函数时抛出的异常。你得到的并不是IllegalArgumentException,因为你没有办法判断实参是不是一个List
。因此类型转换成功,无论如何函数sum都会在这个列表上调用。在这个函数执行期间,异常抛出了。这是因为sum函数试着从列表中读取Number值然后把它们加在一起。把String但Number用的尝试会导致运行时ClassCastException。
/* 对已知类型实参做类型转换 */ fun printSum(c: Collection<Int>) { if (c is List<Int>) { println(c.sum()) //这次检查是合法的 } } >>> printSum(listOf(1, 2, 3)) 6c 时候拥有类型List
的检查是否可行,因为在编译期就确定了集合(不管它是列表还是其他类型的集合)包含的都是整型数字。 Kotlin有特殊的语法结构可以允许你在函数体中使用具体的类型实参,但是又inline函数可以。
9.2.2 声明带实化类型参数的函数
Kotlin泛型在运行时会被擦除,这意味着如果你有一个泛型类的实例,你无法弄清楚在这个实例创建时你究竟用的是那个类型的实参。泛型类型的类型实参也是这样。在调用泛型函数的时候,在函数体中你不能决定函数调用它用的类型实参:
>>> fun <T> isA(value:Any)=value is T //表达式 Error:Cannot check for instance of erased type:T这种情况下只有内联函数能够使用,内联函数的类型形参能够被实化,意味着你可以在运行时应用实际的类型实参。
如果使用inline函数标记函数,编译器会把每次函数调用都换成函数实际的代码实现。使用内联函数还可以提升性能,如果该函数使用了lambda实参:lambda的代码会被内敛,所以不会创建任何匿名类。 inline函数使用时的另一种场景:它们的类型参数可以被实化。
把前面列子中的isA函数声明成inlie并且用reified标记类型参数,你能够用该函数检查value是不是T的实例。
/* 声明带实化类型参数的函数 */ inline fun <reified T> isA(value: Any) = value is T >>> println(isA<String>("abc")) true >>> println(isA<String>(123)) false
一个实化类型参数能够发挥作用最简单的例子就是标准库函数filterIsInstance。这个函数接收一个集合,选择其中哪些指定类的实例,然后返回这些被选中的实例。
/* 使用标准库函数filterIsInstance */ >>> val items = listOf("one", 2, "three") >>> println(items.filterIsInstance<String>()) [one,three]通过指定
作为函数的类型参数,你表明感兴趣的只是字符串。因此函数的返回类型时List 。这种情况下,类型实参在运行时是已知的函数filterIsInstance使用它来检查列表中的值是不是指定为该类型实参的类的实例。 /* filterIsTance声明的简化版本 */ inline fun <reified T> Iterable<*>.filterIsTance(): List<T> { //“reified”声明了类型参数不会在运行时被擦除 val destination = mutableListOf<T>() for (element in this) { if (element is T) { //可以检查元素是不是指定为类型实参的类的实例 destination.add(element) } } return destination }
为什么实化只对内联函数有效?
为什么在inline函数中允许这样写 element is T ,而普通的类或者函数却不行?
编译器把实现内联函数的字节码插入每一次调用发生的地方。每次你调用带实化类型参数的函数时,编译器都知道这次特定调用中用作实参的确切类型。因此,编译器可以生成应用作为类型实参的具体类的字节码。上述 filterIsInstance
for (element in this){
if(element is String){ //引用具体类
destination.add(element)
}
}因为生成的字节码引用了具体类型,而不是类型参数,它不会被运行时发生的类型参数擦除影响。
注意reified类型参数的inline函数不能在java中调用。普通的内联函数可以像常规函数那样在Java中调用–它们可以被调用而不能被内联。带实化类型参数的函数需要额外的处理,来吧类型实参的值替换到字节码中,所以它们必须永远是内联的。所以不能在java中调用。
内联函数在什么情况下性能有势最有效?
一个内联函数可以有多个实化类型参数,也可以同时拥有飞实化类型参数和实化类型参数。注意,filterIsInstance函数虽然被标记成了inline,而他并不期望lamdba作为实参。(决定何时将函数声明为内联函数)中,我们提到函数把函数标记成内联只有在一种情况下有性能优势,即函数拥有函数类型的形参并且其对应的实参–lambda–和函数一起被内联的实化。
为了保证良好的性能,你仍然需要追踪了解标记为inline的函数的大小。如果函数变的庞大,最好把不依赖实化类型参数的代码抽取到非内联函数中。
9.2.3 使用实化类型参数代替类引用
实化类型参数的常见使用场景是为接收java.lang.Class 类型参数的API构造适配器。这个API的例子是JDK中ServiceLoader,它接收一个代表接口或抽象类的java.long.Class,并返回实现了该接口(或继承了该抽象类)java.lang.Class,并返回实现了该接口(或继承了该抽象类)的类的实例。如何利用实化类型参数更容易地调用这些API。
/* 通过类引用 加载ServiceLoader */
val serviceImpl = ServiceLoader.load(Service::class.java)::class.java 的语法展示了如何获取java.lang.Class对应的Kotlin类。
这和Java中的Service.class是完全等同的。
使用实化类型参数的函数重写这个例子:
val serviceImpl = loadService<Service>()代码短了许多。
那么如何定义实化函数?
要加载的服务类现在被指定成了loadService函数的类型实参。把一个类要指定成类型实参要容易理解的多,因为它的代码比使用::class.java语法更短。
看看loadService函数是如何定义的:
inline fun <reified T> loadService(){ //类型参数标记成了“reified”
return ServiceLoader.load(T::Class.java) //把T::Class当成类型形参的类访问。
}这种用在类型上的::Class.java语法也可以用在实化类型参数上。使用这种语法会产生对应到指定为类型参数的类的java.lang.Class,你可以正常使用它。
简化 Android上的startActivity 函数
如果你是Android开发者,可以使用实化类型参数简化startActivity函数。实化类型参数用来代替传递作为java.lang.Class的Activity类。
inline fun <reified T: Activity> Context.startActivity(){ //类型参数标记为“reified”
val intent = Intent(this,T::Class.java) //把T::Class当成类型参数的类访问
startActivity(intent)
}
startActivity(intent) //调用方法显式Activity9.2.4 实化类型参数的限制
实化类型参数是有一些限制的。有一些实化是与生俱来的,另一些是现有的实现决定的,而且可能在未来的Kotlin版本中放开这些限制。
可以按下面的方式使用实化类型参数:
- 用在类型检查和类型转换中(is、!is、as、as?)
- 使用Kotlin反射API(::Class)
- 获取相应的java.lang.Class(::Class.java)
- 作为调用其他函数的类型实参
不能做的事情:
- 创建指定为类型参数的类的实例
- 调用类型参数类的伴生对象的方法
- 调用带实化类型参数函数的时候使用 非实化类型形参作为实参
- 把类、属性或者非内联函数的类型参数标记成reified
最后一条限制的后果:因为实化类型参数只能用于在内联函数上,使用实化类型参数意味着函数和所有给它的lambda都会被内联。如果内联函数使用lambda的方式导致lambda不能被内联,或者你不想lambda因为性能的关系被内联,可以使用noinline修饰符把它们标记成非内联的。
9.3 变型:泛型和子类型化
变型的概念描述了拥有相同基础类型和不同类型实参的(泛型)类型之间是如何关联的。例如:List
9.3.1 为什么存在变型:给函数传递实参
假如你有一个接收List
考虑一个打印出列表内容的函数。
fun printContents(list: List<Any>) {
println(list.joinToString())
}
>>> printContents(listOf("aaa", "bbb"))
aaa,bbb看起来这些字符串列表可以正常工作。函数把每个元素都当成Any对待,而且因为每个字符串都是Any,这完全是安全的。
来看另一个函数它会修改列表(因此它接收一个MutableList作为参数):
fun addAnswer(list: MutableList<Any>) {
list.add(42)
}
>>> val strings = mutableListOf("abc", "bac")
>>> addAnswer(strings) //如果这一行编译通过了
>>> println(strings.maxBy { it.length }) //运行时就会产生异常
ClassCaseException:Integer connot be cast to String你声明了一个类型为MutableList
现在可以回答,把一个字符串列表传给期望Any对象列表的函数是否安全。如果函数添加或者更换了列表中的元素就是不安全的,因为这样会产生类型不一致的可能性。否则它就是安全的。可以通过是否可变选择合适的接口来轻易的控制。如果函数接收的是可读列表,可以传递具有更具体的元素类型的列表。如果列表是可变的,不能这样做。
这些问题可以推广到任何泛型类,而不仅仅是List。接下来会看到为什么两种接口List和MutableList会因为它们的类型参数产生差异。
9.3.2 类、类型和子类型
变量的类型规定了该变量的可能值。有时候我们会把类型和类当成相同的概念使用,当它们不一样,现在来看看它们的区别。
例子非泛型类,类的名称可以当作类型使用。例如,如果你这样些 var x : String,就是声明一个可以保存String类的实例的变量。但是注意,同样的类名称也可以用来声明可空类型:var x:String?。这意味着每个Kotlin类都可以用于构造至少两种类型。
泛型类的情况就变得更加复杂了。要得到一个合法的类型,需要用一个作为类型实参的具体类型替换(泛型)类的类型形参。List不是一个类型(它是一个类),但是下面列举出所有的替代品都是合法类型:List
子类型
为了讨论类型之间的关系,需要熟悉子类型这个术语。任何时候如果需要的是类型A的值,你都能使用类型B的值(当作A的值),类型B就称为类型A的子类型。
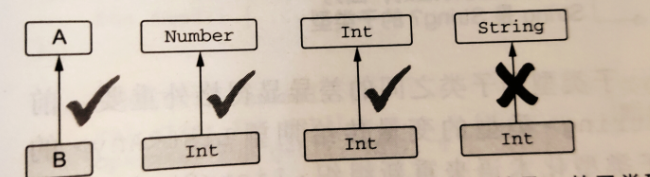
超类型是子类型的反义词。如果B是A的子类型,那A就是B的超类型。
类型是否是另一个子类型的子类型为什么如此重要?
/* 检查一个类型是否是另一个的子类型 */
fun test(i: Int) {
val n: Number = i //编译通过,因为Int是Number的子类型
fun f(s: String) {
/*...*/
}
f(i) //不能编译,因为Int不是String的子类型
}只有值的类型是变量类型的子类型时,才允许变量存储该值。
简单情况下,子类型和子类本质上意味着一样的事务。例如,Int类型是Number的子类,因此Int类型是Number类型的子类型。如果一个类实现了一个接口,它的类型就是该接口类型的子类型:String是CharSequence的子类型。
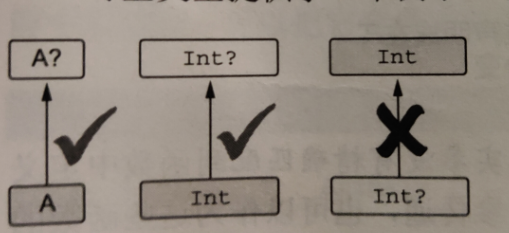
这个例子说明,子类型和子类不是同一事务。
一个非空类型是它的可空类型的子类型,当它们都对应这同一个类。你始终能在可空类型的变量中存储非空类型的值,当反过来却不行(null不是非空类型变量接收的值):
val s:String = "abc"
val t:String ? = s //这次赋值是合法的,因为String是String?的子类型泛型类
当涉及到泛型类时,子类型和子类之间的差异显的格外重要。前面的几个问题,把List
一个泛型类–例如,MutableList–如果对任意两种类型A和B,MutableList< A >既不是MutableList< B >的子类型也不是它的超类型,它就被称为在该类型参数上是 不变型。
什么是协变。
对于这样一个类,List,对它来说,子类型化规则不一样。Kotlin中的List接口表示的是只读集合。如果A是B的子类型,那么List< A >就是List< B >的子类型。这样的类或者接口被称为 协变。
9.3.3 协变:保留子类型化关系
协变
一个协变类是泛型类,对这个类来说,下面的描述是成立的:如果A是B的子类,那么Producer< A >就是Producer< B >的子类。我们说子类型化被保留了。例如,Producer< Cat >是Producer< Animal >的子类型,因为Cat是Animal的子类型。
在声明类时如何说明某个类型参数是可以协变的!
你需要在该类型参数上加上 out 关键词:
interface Producer<out T>{ //类被声明在T上的协变 fun producer():T }将一个类的类型参数标记为协变的,在该类型实参没有精确匹配到函数中定于的类型形参时,可以让该类的值作为这个函数的实际参数,也可以作为这个函数的返回值。
不使用协变的例子会出现的问题:
函数 feedAll 用来负责喂养用类Herd代表的一群动物,Herd类的类型参数确定了畜群中动物的类。
/* 定义一个不变型的类似集合的类 */ open class Animal { fun feed() { /**/ } } class Herd<T : Animal> { // 类型参数没有声明为协变的。 val size: Int get() = operator fun get(i: Int): T { /*...*/ } } fun feedAll(animals: Herd<Animal>) { for (i in 0 until animals.size) { animals[i].feed } }现在需要添加一群猫照顾。
/* 使用一个不变型的类似集合的类 */ class Cat : Animal() { //Cat是一个Animal fun cleanLitter() { ... } } fun takeCareOfCats(cats: Herd<Cat>) { for (i in 0 until cats.size) { cats[i].cleanLitter() // //feedAll(cats } }这时会出现问题,如果你尝试把Cat猫群类传给feedAll函数,在编译器你就会得到类型不匹配的错误。因为Herd类中的类型参数T没有用任何变形修饰符,猫群不是畜群的子类(子类型化没有被保留)。可以使用显式的类型转化来绕过这个问题,但是这种函数啰嗦,易出错,而且从来不是解决类型不匹配问题的正确方法。
Herd类中有一类似List的API,并且不允许它的调用者添加和修改畜群中的动物,可以把它变成协变的并相应修改带用代码。
/*使用一个协变的类似集合的类*/ class Herd<out T : Animal> {// } fun takeCaraOfCats(cats: Herd<Cat>) { for (i in 0 until cats.size) { cats[i].cleanLitter() } feedALl(cats) //不需要转换 }
你不能把任何类都变成协变的:这样不安全。让类在某个类型参数变为协变,限制了该类中对该类参数使用的可能性。要保证类型安全,它只能用在out位置,意味着这个类只能生产(返回)T 的值而不能消费()
在类成员的声明中类型参数的使用可以分为in位置和out位置。考虑怎样一个类,它声明一个类型参数T并包含了一个使用T的函数。如果函数把T当成返回类型,我们说它在out位置,这种情况下,该函数生产类型为T的值。如果T用作函数参数的类型,它就在in位置。这样的函数消费类型为T的值。

约束使用T的位置
类的类型参数前的out关键字要求所有使用T的方法只能把T放在out位置而不能放在in位置。这个关键字约束了使用T的可能性,这保证了对应子类型关系的安全性。
例子
以Herd类为例,它只能在一个地方使用类型参数T:get方法的返回值。
class Herd(out T: Animal) { val size: Int get() = operator fun get(i: Int): T {}//把T作为返回类型使用 }这是一个out位置,可以安全的把类声明成协变的。如果Herd
类的get方法返回的是Cat,任何调用该方法的代码都可以正常工作,因为Cat是Animal的子类型。 类型参数T上的关键字out有两层含义:
- 子类型化会被保留(Producer
是Producer 的子类型) - T只能用在out位置
类型形参可以作为另一个类的类型实参
例
看这个List
interface List<Out T>:Collection<T>{
operator fun get(index: Int):T //只读接口自定义了返回T的方法(所以T在out的位置)
}类型形参不光可以直接当作参数类型或者返回类型使用,还可以当作另一个类型的类型实参。例,List接口包含了一个返回List
interface List<Out T>:Collection<T>{
fun subList(fromIndex: Int, toIndex: Int): List<T> //这里的T在out的位置
}函数subList中的T也用在out位置。
Mutable不能在类型参数上声明成协变的
因为即含有接受类型为T的值作为参数的方法,也含有返回这种值的方法(因此,T出现在in和out两种位置上)。
interface MutableList<T> : List<T>, MutableCollection<T> { //MutableList不能在T上声明成协变的...
override fun add(element: T): Boolean {//...因为T用在了“in”位置
TODO("Not yet implemented")
}
}编译器强制限制了这次协变。如果这个类被声明成了协变,编译器会报告错误:Type parameter T is declared as ‘out’ but occurs in ‘in’ position(类型参数T声明为“out”但出现在“in”位置)。
构造方法
注意,构造方法的参数既不在in位置,也不在out位置。即使类型参数声明成了out,仍然可以在构造方法参数的声明中使用它:
class Herd<Out T:Animal>(vararg animals:T){
...
}如果 把类的实例当成一个类泛化的类型的实例使用,变型会防止该实例被误用:不能调用存在潜在危险的方法。构造方法在实例创建后不会被调用,因此就不会有危险。
然而,如果你在构造方法的参数上使用了关键字val和var,同时就会声明一个getter和setter(如果属性是可变的)。因此对只读属性来说,类型参数用在了out位置, 可变属性在out位置的in位置都是用它:
class Herd<T:Animal>(var leadAnimal:T,vararg animals:T){...}这里 T不能用out标记,因为类包装属性leadAnimal的setter,它在in位置用到了T。
关于设置修饰符
这里位置规则只覆盖了类外部可见的(public、protected、和internal)API。私有方法的参数既不在in位置也不在out位置。变形规则只会防止外部使用者对类的误用但不会对类自己的实现起作用:
class Herd<out T:Animal>(private var leadAnimal:T,vararg animals:T){...}现在可以安全地让Herd在T上协变,因为属性leadAnimal变成了私有的。
如果类型参数在in的位置使用,类和接口会怎样。这是就要有逆变关系成立。
9.3.4 逆变:反转子类型化的关系
概念
逆变的概念可以被看作是协变的镜像:对一个逆变类来说,它的子类型化关系与用作类型实参的类的子类型化关系是相反的。
逆变例子
我们从Comparator接口的例子开始,这个接口定义了一个方法compare类,用于比较两个给定的对象:
interface Comparator<in T> { fun compare(e1: T, e2: T): Int { //在in位置使用T } }这个接口方法只是消费类型为T的值。这说明T只在in位置使用,因此它的声明之前用了in关键字。一个为特定类型的值定义的比较器显然可以比较该类型任意子类型的值。例如,如果有一个Comparator
,可以用它比较任意具体类型的值。 >>> val anyComparator = Comparator<Any> { e1, e2 -> e1.hashCode() - e2.hashCode() } >>> val strings: List<String>=... >>> strings.sortedWith(anyConparator) // 可以用任意对象的比较器比较具体对象,比如字符串sortedWith函数期望一个Comparator< String >(一个可以比较字符串的比较器),传给它一个能比较跟一般的类型的比较器是安全的。如果你在特定类型的对象上执行比较,可以使用能处理该类型或者它的超类型的比较器。这说明Comparator< Any >是Comparator< String >的子类型,其中Any是String的超类型。不同类型之间的子类型关系和这些类型的比较器之间的子类型化关系截然相反。
描述一个逆变类
在 类型参数 上逆变的类是这样的一个泛型类(我们以Consumber< T >为例),对这个类来说,下边的描述是成立的:
如果B是A的子类型,那么Consumer< A >就是Consumer< B >的子类型。类型参数A和B交换了位置,所以我们说子类型化被反转了。例如,Consumer< Animal >就是Consumer< Cat >的子类型。
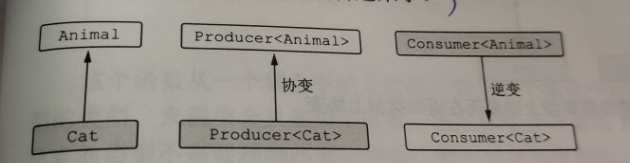
展示了类型参数上协变和逆变的类之间子类型化关系的差异。可以看到对Producer类来说,子类型化关系复制了它的类型实参的子类型化关系,而对Consumer类来说,关系反转了。
in 关键字声明逆变
in 关键字的意思是,对应类型的值是传递进来给这个类的方法的,并且被这些方法消费。和协变的情况类似,约束类型参数的使用将导致特定的子类型化关系。在类型参数T上的in关键字意味着子类型化被反转了,而且T只能用在in位置。
| 协变(方法名称为案例) | 逆变 | 不变型 |
|---|---|---|
| Producer< out T> | Consumer< in T> | MutableList< T> |
| 类的子类型化保留了:Producer< Cat>是Producer< Animal>的子类型 | 子类型化反转了:Consumer< Animal>是Consumer< Cat>的子类型 | 没有子类型化 |
| T只能在out位置 | T只能在in位置 | T可以在任何位置 |
一个类可以在一个类型参数上协变,同时在另一个类型参数上逆变。Function接口的例子。
interface Function1<in P, out R> {
operator fun invoke(p: P): R
}Kotlin的表示法(P)->是表达Function<P,R>的另一种可读性的形式。可以发现用in关键字标记P(参数类型)只用在in位置,而用out关键字标记的R(返回类型)只用在out位置。这意味着对这个函数类型的第一个类型参数来说,子类型化反转了,而对第二个类型参数来说,子类型化保留了。
例,你有一个高阶函数,该函数尝试对里所有的猫进行迭代,你可以把一个接收任意动物的lambda传给它。
fun enumerateCats(f: (Cat) -> Number) {
...
}
fun Animal.getIndex(): Int = ...
>>> enumerateCats(Animal::getIndex) //在Kotlin中这段代码是合法的。Animal是Cat的超类型,而Int是Number的子类型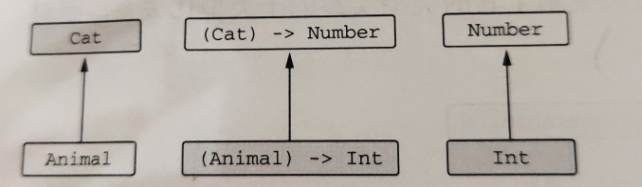
9.3.5 使用点变形:在类型出现的地方指定变型
声明点变型
在类声明的时候就能够指定变形修饰符是很方便的,因为这些修饰符会应用到所有类被使用的地方。所以被称为声明点变型
使用点变型
如果你熟悉Java的通配符类型(? extends 和 ? super),你会意识到Java用完全不同的方式处理类型。在Java中,每一次使用带类型参数的类型的时候,还可以指定这个类型参数是否可以用它的子类型或者超类型替换。这叫做 使用点变型
Kotlin 支持使用,使用点变型
Kotlin支持使用点变型,允许在类型参数出现的具体位置指定变型,即使在类型声明时不能被声明成协变或逆变的。
看看使用点变型是如何工作的
许多MutableList这样的接口,通常情况下既不是协变也不是逆变的,因为它同时生产和消费指定为它们类型参数的类型的值。但是对于这个类型的变量来说,在某个特定函数中只被当成其中一种角色使用的情况很常见:要么是生产者要么是消费者。例如
/* 带不变型类型参数的 数据拷贝函数 */ fun <T> copyData(source: MutableList<T>, destination: MutableList<T>) { for (item in source) { destination.add(item) } }这个函数从一个集合中把元素拷贝到另一个集合中。尽管两个集合都拥有不变型的类型,来源集合只是用于读取,而目标集合只是用于写入。这种情况下,集合元素的类型不需要精确匹配。例如,把一个字符串集合拷贝到可以包含任何集合中一点问题没有。
让函数支持不同类型的列表,引入第二泛型参数
/* 9.15 带不变型类型参数的数据拷贝函数 */ fun <T : R, R> copyData(source: MutableList<T>, destination: MutableList<R>) { //来源的元素类型应该是目标元素类型的子类型 for (item in source) { destination.add(item) } } >>> val ints = mutableListOf(1, 2, 3) >>> val anyItems = mutableListOf<Any>() >>> copyData(ints,anyItems) //可以调用这个函数,因为Int是Any的子类型 >>> println(anyItems) [1,2,3]你声明了两个泛型参数代表 来源列表和目标列表中的元素类型。为了能够把一个列表中的元素拷贝到另一个列表中,来源元素类型应该是目标列表中的元素的子类型,例如 9.15中的Int是Any的子类型。
另一种方式支持不同列表。
Kotlin提供了更优雅的表达方式。当函数的实现调用了那些类型参数只出现在out位置(或只出现在in位置)的方法时,可以充分利用这一点,在函数定义中给特定用途的类型参数用上变型修饰符
/* 9.16 带out投影类型参数的数据拷贝函数 */ fun <T> copyData( source: MutableList<out T>, destination: MutableList<T> ) { for (item in source) { destination.add(item) } }可以为类型声明中类型参数任意的用法指定变型修饰符,用法包括:形参类型、局部变量类型、函数返回类型、等。这发生的一切都叫做 类型投影:我们说source不是一个常规的MutableList,而是一个投影受限的MutableList。只能调用返回类型是泛型类型参数的那些方法。编译器禁止调用使用类型参数做实参(类型)的哪些方法(在in位置使用类型参数):
>>> val list: MutableList<out Number> = ... >>> list.add(42) Error:Out-projectedType 'MutableList<out NUmber>' prohibits the use of 'fun add(element:E):Boolean'(在in位置使用类型参数后调用类型参数方法是不可取的。)
不要为使用投影类型参数后不能调用某些方法而吃惊。如果需要调用那些方法,你需要的是常规类型而不是投影。这可能要求你声明第二类型参数,它依赖的是原本要进行投影的类型,例 9.15 中那样。
因为我们只用了声明在List中的方法,并没有用到MutableList中的方法,而且List类型参数的变型在声明时就指定了。所以实现copyData函数的正确方式应该是使用List
作为source实参的类型。这个例子展示这种概念依然十分重要,尤其是要记住大多数的类并没想List和MutableLIst这样分开两个接口,一个是协变的读取接口,一个是不变型的读取/写入接口。 在类型参数有out变型时投影没有意义
如果类型阐述已经有out变型,获取它的out投影没有任何意义。就像List
这样。它和List 是同一个意思,因为List已经声明成了class List 。Kotlin编译器会发出警告,表明这些投影是多余的。 同理,对类型参数的用法使用in修饰符,来表明这个特定的地方,相应的值担当的是消费者,而且类型参数可以任意使用它的子类型替换。
用in来重写部分代码(9.16).
fun <T> copyData(source: MutableList<T>, destination: MutableList<in T>) {//允许目标元素的类型是来源类型的超类型 for (item in source) { destination.add(item) } }注意:Kotlin的使用点变型直接对应Java的限界通配符。Kotlin 中的MutableList
和Java 中的MutableList<? extends T>是一个意思。in投影是一个意思。in 投影的MutableList 对应到Java的MutableList<? super T>。
(优点)使用点变型有助于放宽可接受的类型范围。讨论另一种极端情况:这种情况下(泛型)类型使用所有可能的类型实参。(泛型要使用所有可能的类型)
9.3.6 星号投影:* 代替类型参数
在提到类型检测和转换的时候,我们提到了一种特殊的 星号投影 语法,可以用它来表明你不知道关于泛型实参的任何信息。
List<*>表示为一个未知类型的元素的列表用这种语法表示。
星号投影的含义
首先 ,需要注意的是MutableList<*>和MutableList<Any?>不一样(这里MutableList
>>> val list: MutableList<Any?>=mutableListOf('a', 1, 'qwe')
>>> val chars = mutableListOf('a', 'b', c)
>>> val unknownElements: MutableLIst<*> = // MutableList<*>和MutableList<Any?>不一样。
if (Random().nextBoolean())
list
else
chars
>>> unknownElements.add(42) //编译器禁止调用这个方法
Error: Out-projected type 'MutableList<*>' prohibits the use of 'fun add(element:E): Boolean'
>>> println(unknownElements.first()) // 读取元素是安全的:first.()返回一个类型为Any?的元素。
3为什么编译器会把 MutableList< * > 当成out投影的类型?(out-projected)。 在这个例子的上下文中, MutableList< * >投影成了MutableList<Any?>: 当你没有任何元素类型信息的时候,读取Any?类型的元素仍然是安全的, 但是向列表中写入元素是不安全的。
注意:
对于Consumber
这样的逆变类型参数来说,星号投影等价于 。实际上这种星号投影无法调用任何签明中有T的方法。如果类型参数是逆变的,它就只能表现为一个消费者,你不知道它消费的到底是什么。
场景
当类型实参的信息并不重要的时候,可以使用星号投影的语法:不需要使用任何在签名中引用类型参数的方法,或者只是读取数据而不关心它的具体类型。列入,可以实现一个接收List<*>做参数的printFirst函数:
fun printFirst(list: List<*>) { // 每一种列表都可能是实参。 if (list.isNotEmpty()) { // isNotEmpty()没有使用泛型类型参数 println(list.first()) // fist()现在返回的是Any?,但在这里足够了 } } >>> printFirst(listOf('Svetlana','Dmitry')) Svetlana使用点变型的情况下,有一个代替方案–引入一个泛型类型参数:
fun <T> printlnFirst(list: List<T>) { // 每一种列表都是可能的实参 if (list.isNotEmpty()) { println(list.first()) //first()现在返回的是T的值。 } }星号投影的语法很简洁,但只能用在对泛型类型实参的确切值不感兴趣的地方:只是使用生产值的方法,而且不关心那些值的类型。
场景
另一个使用星号投影的日子,以及使用这种方法时会困扰你的陷阱。
假如你需要验证用户的输入,并声明一个接口FieldValidator。它只包含在in位置的类型参数,所以声明成了逆变的。事实上,当期望的是字符串验证器时使用可验证任意元素的验证器也是没有问题的(这就是声明成逆变带来的效果)。同时还声明了两个验证器来分别处理String和Int。
/* 9.18 输入验证的接口 */ interface FieldValidator(in T) { //接口定义成 在 T 上的逆变。 fun validete(input: T): Boolean // T只在“in"位置使用(这个方法只消费T的值)。 } object DefaultStringValidator : FieldValidator<String> { override fun validate(input: String) = input.isNotEmpty() } object DefaultIntValidator : FieldValidator<Int> { override fun validate(input: int) = input >= 0 }现在假设你想要把所有的验证器都存储到同一个容器中,并根据输入的类型来选出正确的验证器。首先会用到map来存储它们。你存储的是任意类型的验证器,所以你声明了KClass(代表一个Kotlin类,10章会详细介绍KClass)到FiledValidator<*>(可以指向任意类型的验证器)的map:
>>> validators = mutableMapOf<KClass<*>,FieldValidator<*>>() //key ,value >>> validators[String::class] = DefaultStringValidator >>> validators[Int::class] = DefaultIntValidator如果你这样做了,尝试使用验证器的时候就会遇到困难。不能用类型为FieldValidator<*>的验证器来验证字符串。这是不安全的,因为编译器不知道它是那种验证器:
>>> validators[String::class]!!.validate("") //存储在map中的值的类型是FieldValidator<*>。 Error:Out-projected type 'FieldValidator<*>' prohibits the use of 'fun validate(intput: T):Boolean'(写入时会报错)在前面尝试向MutableList<>中写入元素的时候,你已经见过这种错误了。这种情况下,这个错误的意思是把具体类型的值传给未知类型的验证器是否安全的。*一种修正方法是把验证器显式地转换成需要的类型。这样做是不安全的,也是不推荐的。但我们还是把他作为让代码快速通过编译的技巧展示在这里,这样可以在后面重构它。**
/* 9.19 使用显式的转换获取验证器 */ >>> val stringValidator = validators[String::class] as FieldValidator<String> //警告未受检的转换 >>> println(stringValidator.validate("")) false编译器发出了未受检转换的警告。注意,尽管如此,这段代码只有在验证时可以失败,而不是在转换时,因为运行时所有的泛型信息都被擦除了。
/* 9.20 错误的获取验证器 */ >>> val stringValidator = validators[Int::class]// 得到一个错误的验证器(可能为不小心0,但代码可以编译。(获取一个Int强制转换为String) as FieldValidator<String> // 仅仅一个警告 >>> stringValidator.validate("") //直到使用验证器才发现错误。 java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Number at DefaultIntValidator.validate这两段代码在两种情景下是相似的,都只会发出警告。这些强制转换导致类型不安全,也容易出错。如果想要把不同类型的验证器存储在同一个地方,我们要研究一下其他的选择。
代码 9.21 中使用解决方法 map validators,但是把所有对它的访问封装到了两个泛型方法中,它们负责保证只有正确的验证器被注册和返回。这段代码依然会发出未受捡转换的警告(这之前的一样),但这里的Validators对象控制了所有对map的访问,保证了没有任何人会错误的改变map。
/* 9.21 封装对验证器集合的访问 */
object Validators {
private val validators = = mutableMapOf<KClass<*>, FieldValidator<*>>() //使用和之前一样的map,但现在无法在外部访问他
fun <T : Any> registerValidator(
kCLass: KClass<T>, fieldValidator: FieldValidator<T>
) {
validators[kClass] = fieldValidator // 只有正确的键值对被写入map,即但验证器正好对应到类的时候。
}
@Suppress("UNCHECKED_CAST") // 禁止关于未受检的转换到FieldValidator<T> 的警告
operator fun <T : Any> get(kClass: KClass<T>): FieldValidator<T> =
validators[kCLass] as? FieldValidator<T> ?: throw IllegalArgumentException(
"No validator for ${kClass.simpleName}"
)
}
>>> Validators.registerValidator(String::class, DefaultStringValidator)
>>> Validators.registerValidator(Int::class,DefaultIntValidator)
>>> println(Validators[String::class].validate("Kotlin"))
true
>>> println(Validators[Int::class].validate(42))
true你拥有了一个类似安全的API。所有不安全的逻辑都被隐藏在类的主体中,通过把这些逻辑局部化,保证了它不会被错误的使用。编译器禁止使用错误的验证器,因为Validatos对象始终都会给出正确的验证器实现。
>>> println(Validators[String::class].validate(42))
Error:The integer literal does not conform to the expected type String通过封装验证器集合的模式可以轻松的推广到任意自定义泛型类的存储。把不安全的代码局部化到一个分开的位置预防了误用,而且让容器的使用变的安全。这个模式并不是只针对Kotlin,Java中也可以使用同样的方法。
9.4 小结
- Kotlin的泛型同Java的泛型接近它们使用同样的方式声明泛型函数和泛型类。
- 同Java一样,泛型类型的类型实参只在编译器存在。
- 不能把带类型实参的类型和is运算符一起使用,因为类型实参在运行时不被擦除。
- 内联函数的类型参数可以标记成实化的,允许你在运行时对它们使用is检查,以及获得java.lang.Class实例
- 变型是一种说明两种拥有相同基础类型和不同类型参数的泛型类型之间子类型化关系的方式,它说明了如果其中一个泛型类型的类型参数是另一个的类型参数的子类型,这个泛型类型就是另外一个泛型类型的子类型或者超类型。
- 声明一个类在某个类型上是协变的,该参数只能用在out位置。
- 逆变情况相反:可以声明一个类在某个类型参数上是逆变的,如果该参数只是用在in位置。
- Kotlin中只读接口List声明成了逆变,这意味着List< String > 是 List< Any >的子类型
- 函数接口声明成了在第一个类型参数上逆变而在第二个接口上协变,使(Animal)->Int称为(Cat)->Number的子类型。
- 在Kotlin中即可以为整个泛型类指定变型(声明点变型),也可以为泛型类型特定的使用指定变型(使用点变型)。
- 当确切的类型实参是未知的或者不重要时,可以使用星号投影语法。
10 注解和反射
要调用一个函数,你需要知道定义在哪个类中,还有它的名称和参数的类型。 注解和反射给你超越这个规则的能力,并让你编写出使用事先未知的任意类的代码。可以使用注解赋予这些类库特定的语义,而反射允许你在运行时分析这些类的结构。
应用注解非常直接了当。但编写你的注解尤其是编写处理它们的代码,就没有这么简单了。使用注解的语法鱼Java完全相同,而声明自己注解类的语法却略有不同。 反射API的大体结构与Java相仿,但细节存在差异。
作为注解和反射用法的演示,我们将会带你浏览一个真实项目的实现:一个叫做JKid的库,用来序列化和反序列化JSON。这个库在运行时用反射访问任意的Kotlin对象,同时还根据JSON文件中提供的数据创建对象。注解则可以让你定制具体的类和属性是如何被这个库序列化和反序列化的。
地址:https://github.com/TheCara/jkid
10.1 声明并应用注解
Kotlin 中的核心概念是一样的。一个注解允许你把额外的元数据关联到一个声明上。然后元数据就可以被相关的源代码工具访问,同个编译好的类文件或是在运行时,取决于这个注解是如何配置的。
10.1.1 应用注解
在Kotlin中使用注解的方法和Java中一样。要应用一个注解,以@字符作为(注解)名字的前戳,并放在要注解的声明最前面。可以注解不同的代码元素,比如函数和类。
例如,使用框架JUnit(http://junit.org/junit4),可以用@Test标记一个测试方法:
import org.junit.*
class MyTest {
@Test
fun testTrue() { //@Test注解指引Junit框架把这个方法当测试调用
Assert.assertTrue(true)
}
}另一个更有趣的例子:@Deprecated注解。它在Kotlin总的含义与java一样(@Deprecated 注解含义:意思为此方法已过时,因为有了新的API代替它。)但是Kotlin用replaceWith参数增强了它,让你可以提供 一个替代者的(匹配)模式,以支持平滑的过渡到API的新版本。
如何给一个注解提供实参(一条 不推荐使用 的信息和一个 替代者 的模式:
@Deprecated("Use removeAt(index) instead.",RepalceWith("removeAt(Index)"))
fun remove(index:Int){ ... }实参在括号中传递,就和常规函数的调用一样。用了这个声明之后,如果有人使用了remove函数,IntelliJ IDEA 不仅会提示应该使用哪个函数来使用它(这个例子中removeAt),还会提供一个自动的快速修正。
注解只能拥有如下类型的参数:基本数据类型、字符串、枚举、类引用、其他的注解类,以及前面这些类型的数组。指定注解的实参与Java有微小差别:
- 要把一个类指定为注解实参,在类名后加上 ::class :@MyAnnotation(MyClass::class) 。
- 要把另一个注解指定为一个实参,去掉注解名称前的@。例如,前面例子中的ReplaceWith是一个注解,但是你把它指定为Deprecated注解的实参时没有用@。
- 要把一个数组指定为一个实参,使用arrayOf函数:@RequestMapping(path=arrayOf(“/foo”,”/bar”))。如果注解类是在Java中声明的,命名为value的形参按需自动地被转换成可变长度的形参,所以不用arrayOf函数就可以提供多个实参。
注解实参需要在编译期就是已知的,所以你不能引用任意的属性作为实参。要把属性当作注解实参使用,你需要用const修饰符标记它,来告知编译器这个属性是 编译期常量。
下面一个JUnit@Test注解的例子,使用timeout参数测试超时时长,单位为毫秒:
const val TEST_TIMEOUT = 100L
@Test(timeout = TEST_TIMEOUT) fun testMethod(){ ... }在使用const标注的属性可以声明在一个文件的顶层或者一个object之中,而却必须初始化为基本数据类型或者String类型的值。如果你尝试使用普通属性作为注解实参,将会得到一个错误“Only ‘const val’ can be used in constant expressions.”(只有‘const val’才能用在常量表达式中)。
10.1.2 注解目标
多数情况下,Kotlin源代码中的单个声明会对应多个Java声明,而且它们每个都能携带注解。例如,一个Kotlin 属性就对应了一个Java字段,getter,以及一个潜在的setter和它的参数。而一个在主构造方法中声明的属性还多拥有一个对应的元素:构造方法的参数。因此,说明这些元素中那些需要注解十分必要。
使用点目标声明被用来说明要注解的元素。使用点目标被放在@符号和注解名称之间,并用冒号和注解名分开。下列单词get导致注解@Rule被应用到了属性的getter上。
@get:Rule
// get(使用点目标) Rule(注解目标)下面看一个使用这个注解的例子。在JUnit中可以指定一个每个测试方法被执行之前都会执行的规则。例,标准的TemporaryFolder规则用来创建文件和文件夹,并在测试结束后删除它们。
使用 ”使用点目标声明“ 以及注意事项!
要指定一个规则,在Java中需要声明一个用@Rule的注解的public字段或者方法。如果在你的Kotlin测试类中只是用@Rule注解了属性folder(包含字段folder?)你会得到一个JUnit一场:“The(???)’folder’ must be public.”((???)’folder’必须是公有的。)这是因为@Rule被应用到了字段上,而字段是默认是私有的。要把它应用到(公有的)getter上,要显式的写出来,@get:Rule 如下:
class HasTempFolder {
@get:Rule // 注解的是getter,而不是属性
val folder = TemporaryFolder()
@Test
fun testUsingTempFolder() {
val createFile = folder.newFile("myfile.txt")
val createFolder = folder.newFolder("subfolder")
// ...
}
}如果你使用Java中声明的注解来注解一个属性,它会被默认的应用到相应的字段上。Kotlin 也可以让你声明被直接对应到属性上的注解。
Kotlin支持的使用点目标的完整列表如下:
- property——Java的注解不能应用这种使用点目标。
- field——为属性生成字段。
- get——属性的getter。
- set——属性的setter。
- receiver——扩展函数或者扩展属性的接收者参数。
- param——构造方法的参数。
- setparam——属性的setter的参数。
- delegate——为委托属性存储委托实例的字段。
- file——包含在文件中声明的顶层函数和属性的类。
任何应用到file目标的注解都必须放在文件的顶层,放在package指令之前。@JvmName是常见的应用到文件的注解之一,它改变了对应类的名称。
和Java不一样的是,Kotlin允许你对任意的表达式应用注解,而不仅仅是类和函数的声明以及类型。最常见的例子就是@Suppress注解,可以用它遏制被注解的表达式的上下文中的特定的编译器警告。下面就是一个注解的局部变量声明的例子,抑制了未受捡转换的警告:
fun test(list: List<*>) {
@Suppress("UNCHECKED_CAST")
val string = list as List<String>
// ...
}用注解控制JavaAPI
Kotlin 提供了各种注解来控制Kotlin编写的声明如何编译成字节码并暴露给Java调用者。其中一些注解代替了Java语言中对应的关键字:比如,注解@Volatile和@Strictfp直接充当了Java的关键字volatile和strictfp的替身。其他的注解则被用来改变Kotlin声明对Java调用者的可见性:
- @JvmName将改变由Kotlin生成的Java方法或字段名称。
- @JvmStatic能被用在对象声明或者伴生对象的方法上,把它们暴露成Java的静态方法。
- @JvmOverloads,指导Kotlin编译器为带默认参数值的函数生成多个重载(函数)。
- @JvmField可以应用于一个属性,把这个属性暴露成一个没有访问器的公有Java字段。
10.1.3 使用注解定制JSON序列化
注解的典型用法之一就是定制化对象的序列化。序列化 是一个过程,把对象转换成可以存储或者在网络上可以传输的二进制或者文本的表达式。它的逆向工程可以 反序列化 ,把这种表达法转换回对象。而最常见的一种用来序列化的格式计算JSON。 有很多广泛使用的库可以把Java对象序列化成JSON,包括Jackson和GSON。这些对Kotlin完全兼容。
将会讨论一个满足此用途的名为JKid的纯Kotlin库。它足够小巧,可以轻松的读完它的全部源代码。
JKid 库源代码和练习
JKid 地址:https://github.com/yole/jkid。要学习库的实现和例子,在IDE中把文件 ch10/jkid/build.gradle 作为Gradle项目打开。在项目的 src/test/kotlin/examples 目录下可以找到这些例子。它并不像GSON或者Jackson那样完善灵活,但它的性能足够使用。
先从简单的例子开始,测试这个库:序列化和反序列化一个Person类的实例。把实例传递给serialize函数,然后它就会返回一个包含该实例JSON表示法的字符串:
data class Person(val name:String,val age:Int)
>>> val person = Person("Alice",29)
>>> println(serialize(person))
{"age":29,"name":"Alice"}一个对象的JSON表达法由键值对组成:具体实例的属性名称和它们的值之间的键值对,比如:“age”:29 。
要从JSON表达法中取回一个对象,要调用deserialize函数:
>>> val json="""{"name":"Alice","age":29}"""
>>> println(deserialize<Person>(json))
Person(name=Alice,age = 29)当你从JSON数据中创建实例的时候,必须显式的指定一个类作为类型参数,因为JSON没有存储对象的类型,这种情况下,你要传递Person类。
下图,展示了一个对象和它的JSON表示法之间的关系。注意序列化之后的类能包含的不仅是图中展示的这些基本数据类型或者字符串类型的值,还可以是集合,以及其他值对象类的实例。
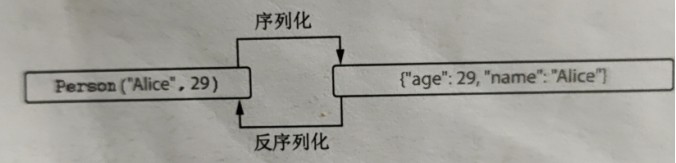
你可以使用注解来定制对象序列化和反序列化的方式。当把一个对象序列化成JOSN的时候,默认情况下这个库尝试序列化的所有属性,并使用属性名称作为键。注解允许你改变默认的行为,两个注解,@JsonExclude和@JsonName,稍后查看它们的实现:
- @JsonExclude注解用来标记一个属性,这个属性应该排除在序列化和反序列化之外。
- @JsonName注解让你说明代表这个属性的(JSON)键值对中的键应该是一个给定的字符串,而不是属性的名称。
参考一个例子:
data class Person {
@JsonName("alias")
val firstName: String,
@JsonExclude
val age: Int? = null
}你注解了属性firstName,来改变JSON中用来表示它的键。而属性age也被注解了,在序列化和反序列化时会排除它。注意你必须指定age的默认值。否则,在反序列化时你无法创建一个Person的新实例。 如下展示了Person内实例的表示法发生了怎样的变化。
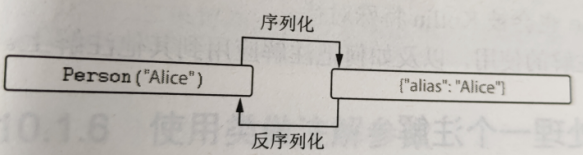
键名是@JsonName注解的字符串“alias”。
已经见过了JKid中出现的大多数功能:serialize()、deserialize()、@JsonName和@JsonExclude。讨论如何实现它们吧。
10.1.4 声明注解
这次你会以JKid库中的注解为例学习怎样声明他们。注解@JsonExclude有着最简单的形式,因为它没有任何参数:
annotation class JsonExclude语法看起来和普通类的声明很像,只是在class关键词之前加上了annotation修饰符。因为注解类只是用来定义关联到声明和表达式的元数据的结构,它们不能包含任何代码。因此,编译器禁止为一个注解类指定主体。
对拥有参数的注解来说,在类的主构造方法中声明这些参数:
annotation class JsonName(val name:String)你用的是常规的主构造方法的声明语法。对一个注解类的所有参数来说,val关键字是强制的。
/* Java */
public @interface JsonName{
String value();
}注意,Java注解拥有一个叫做value的方法,而Kotlin注解拥有一个name属性。Java中value方法很特殊:当你应用一个注解时,你需要提供value以外所有指定特性的显式名称。而另一方面,在Kotlin中应用注解就是常规的构造方法调用。可以使用命名实参语法让实参的名称变成显式的,或者可以省略掉这些实参的名称:@JsonName(name = “first_name”) 和 @JsonName(“first_name”)含义一样。因为name是JsonName构造方法的第一个形参(它的名称可以省略)。(Kotlin中如何使用Java中声明的注解?)然而,如果你需要把Java中声明的注解应用到Kotlin元素上,必须对除啦value以外的所有实参使用命名实参语法,而value也会被kotlin特殊对待。
如何控制注解的使用,以及如何把注解应用到其他注解上。
10.1.5 元注解:控制如何处理一个注解
和Java一样,一个Kotlin注解类自己也可以被注解。可以应用到注解类上的注解被称为元注解。标准库中定义了一些元注解,它们会控制编译器如何处理注解。其他一些框架也会用到元注解——例如,许多依赖注入库使用了元注解来标记其他注解,表示这些注解用来识别拥有同样类型的不用的可注入对象。
标准库定义的元注解中最常见的就是@Target。JKid中@JsonExclude和@JsonName的声明中使用它为这些注解指定有效的目标。下面展示它们是如何应用到这些注解上的。
@Traget(AnnotationTarget.PROPERTY)
annotation class JsonExclude@Target 元注解说明了注解可以被应用到元素类型。如果不使用它,所有的声明都可以应用这个注解。这并不是JKid想要的,因为它只处理属性的注解。
AnnotationTarget枚举的值列出了可以应用注解的全部可能目标。例如:类、文件、函数、属性、属性访问器、所有的表达式,等等。如果需要,你还可以声明多个目标:@Target(AnnotationTarget.CLASS,AnnotationTarget.METHOD)。
要声明你自己的元注解,使用ANNOTATION_CLASS作为目标就好了
@Target(AnotationTarget.ANNOTATION_CLASS)
annotation class BindingAnnotation
@BindingAnnotation
annotation class MyBinding在Java代码中无法使用目标PROPERTY的注解:要让这样的注解在Java中使用,可以给它添加第二个目标AnnotationTarget.FIELD。这样注解既可以应用到Kotlin中的属性上,也可以应用到Java中的字段上。
@Retention 注解
你也许在Java中见过另一个重要的元注解:@Retention。它被用来说明你声明的注解时候会存储到.class文件,以及在运行时是否可以通过反射来访问它。Java默认会在.class文件中保留注解但不会让它们在运行期间被访问到。大多数注解确实需要在运行时存在,所以Kotlin的默认行为不同:注解拥有RUNTIME保留期。因此JKid中的注解没有显示地指定保留期。
10.1.6 使用类做注解参数
你已经见过了如何定义保存了作为其实参的静态数据的注解,但有时候你有不同的需求:能够引用类作为声明的元数据。你可以通过声明一个拥有类引用作为形参的注解类来做到这一点。在JKid库中,这出现在@DeserializeInterface注解中,它允许你控制那些接口类型属性的反序列化。不能直接创建一个接口的实例,因此需要指定反序列化时那个类作为实参被创建。
展示这个注解如何使用:
interface Company{
val name:String
}
data class CompanyImpl(override val name:String):Company
data class Person(val name:String, @DeserializeInterface(CompanyImpl::class) val company:Company
)当JKid读到一个Person类实例嵌套的company对象时,它创建并反序列化了一个CompanyImpl实例,把它存储在company属性中。(说明反序列化)使用CompanyImpl::class 作为@DeserializeInterface注解的实参来说明这一点。通常,使用类名称后面跟上::class关键字来引用一个类。
现在我们看看这个注解是如何声明的。(声明类作为注解参数)它的单个实参是一个类的引用,就像@DeserializeInterface(CompanyImpl::class):
annotation class DeserializeInterface(val targetClass:KCLass<out Any>)KClass是Java的java.lang.Class类型在Kotlin中的对应类型。它用来保存Kotlin类的引用。
KClass的类型参数说明了这个引用可以指向哪些Kotlin类。例如,CompanyImpl::class 的类型是KClass< CompanyImpl >,它是这个注解形参类型的子类型,例如:
如果你只写出KClass< Any > 而没有写出out修饰符,就不能传递CompanyImpl::class 作为实参:唯一允许的实参将是Any::class 。out关键字说明允许引用哪些继承Any的类,而不仅仅是引用Any自己。
10.1.6 使用泛型类作为注解参数
默认情况下,JKid把非基本数据类型(基本数据类型以外)的属性当成嵌套的对象序列化。但是你可以改变这种行为并为某些值提供你自己的序列化逻辑。
@CustomSerializer注解接收一个自定义序列化器类的引用作为实参。这个序列化器类应该实现ValueSerializer接口
interface ValueSerializer<T>{
fun toJsonValue(value:T):Any?
fun fromJsonValue(jsonValue:Any?):T
}假设你需要支持序列化日期,而且已经为此创建了你自己的DateSerializer类,它实现了ValueSerializer< Data > 接口(这个类是JKid源代码中的一个例子:http://mng.bz/73/a7 )展示如何在Person类应用它:
data class Person(
val name:String,
@CustomSerializer(DataSerializer::class) val birthDate:Date)现在我们看看@CustomSerializer注解是如何声明的。ValueSerializer类是泛型的而且定义了一个类型形参,所以在你引用该类型的时候需要提供一个类型实参值。因为你不知道任何关于那些应用了这个注解的属性类型的信息,可以 使用 星号投影 作为类型实参:
annotation class CustomSerializer(
val serializerClass: KClass<out ValueSerializer<*>>
)下图,审视了seralizerClass 参数的类型并解释了其中不同的部分。(声明时限制了范围)你需要保证注解只能引用实现了ValueSerializer接口的类。(声明时限制了范围)例如,@CustomSerializer(Data::class)的写法是不允许的,因为Data没有实现ValueSerializer接口。

这好像很麻烦,好消息是每一次需要使用类作为注解实参的时候都可以应用同样的模式。如写KClass< out YourClassName >,如果YourClassName有它自己的类型实参,就用 * 代替它们。
下面讨论如何访问存储在这些注解中的数据。你需要使用反射做到这些。
10.2 反射:在运行时对Kotlin对象进行自省
反射,简单来说,(什么是反射?)一种在运行时动态地访问对象属性和方法的方式,而不需要事先确定这些属性是什么。 (为什么使用反射或者什么时候使用反射)*一般来说,当你访问一个对象的方法或者属性时,程序的源代码会引用一个具体的声明,编译器将静态地解析这个引用并确保这个声明是存在的。但有些时候,你需要编写能够使用任意类型的对象的代码,或者只能在运行时才能确定要访问的方法和属性的名称。JSON序列化库就是这种代码绝好的例子:它要能够把任何对象都序列化成JSON,所以它不能引用具体的类和属性。这时就运用到反射了。*
(Java完美支持Kotlin反射)当在Kotlin中使用反射时,你会和两种不同的反射API打交道。第一种是标准的Java反射,定义在包java.lang.reflect中。因为Kotlin类会被编译成普通的Java字节码,Java反射API可以完美地支持它们。实际上,这意味着使用了反射API的Java库完全兼容Kotlin代码。
第二种是Kotlin反射API,定义在包kotlin.reflect中。它让你能访问那些在Java世界你不存在的概念,诸如属性和可空类型。但这一次它没有为Java反射API提供一个面面俱到的替身,而且不久你就会看到,有些情况下你仍然会回去使用Java反射。这里有一个重要提示,Kotlin反射API没有仅限于Kotlin类:你能够使用同样的API访问用任何JVM语言写成的类。
注意:在一些特别在意运行时库的大小的平台上,例如Android,为了降低大小,Kotlin反射API被打包成了单独的jar.文件,即kotlin-reflect.jar。它不会被默认地添加到新项目的依赖中。如果你正在使用Kotlin反射API,你要确保这个库作为依赖被添加(到项目中)。IntelliJ IDEA能够检查到缺失的依赖并协助你添加它。(这个库的 Maven group/artifact 坐标是 org.jetbrains.kotlin:kotlin-reflect。)
10.2.1 Kotlin反射:KClass、KCallable、KFunction和KProperty
Kotlin反射API的主要入口就是KClass,它代表一个类。KClass对应的是java.lang.class,可以用它来列举和访问类中包含的所有声明(列举运行时的所有类和声明),然后它的超类型中的声明,等等。MyClass::class 的写法会带给你一个KClass的实例。要在运行时取得一个对象的类,首先使用javaClass属性获得它的Java类,这直接等价于Java中java.lang.Object.getClass()。然后访问该类的.kotlin扩展属性,从Java切换到Kotlin的反射API。
class Person(val name:String,val age:Int)
>>> val person = Person("Alice",29)
>>> val kClass = person.javaClass.kotlin //返回一个KClass<Person>的实例
>>> println(kClass.simpleName)
person
>>> kClass.memberProperties.forEach { println(it.name) }
age
name这个简单的例子打印出了类的名称和它的属性的名称,并且使用.memberProperties来收集这个类,以及它的所有超类中定义的全部会扩展属性(age和name)。
如果浏览一下KClass的声明,你就会发现包含大量的方法,用来访问类的内容:
interface KClass<T:Any>{
val simpleName:String?
val qualifiedName:String?
val members:Collection<KCallable<*>>
val constructors:Collection<KFunction<T>>
val nestedClasses:Collection<KClass<*>>
...
}KClass的许多有用的特性,包括前面例子中用到的memberProperties,都声明成了扩展。可以在标准库参考(http::mng/bz/em4i)中看到完整KClass方法类列表。
你可能已经发现了由类的所有成员组成的列表是一个KCallable实例的集合(KClass声明中有提到)。KCallable是函数和属性的超接口。它声明了call方法,允许你调用对应的函数或者对应属性的getter:
interface KCallable<out R>{
fun call(vararg age:Any?):R
}你把(被引用)函数的实参放在varage列表中提供给它。↓展示如何通过反射使用call来调用一个函数:
fun foo(x:Int) = println(x)
>>> val kFunction = ::foo
>>> kFunction.call(42)
425.1.5节中有见过::foo 语法,现在可以发现这个表达式的值是来自反射API的KFunction类的一个实例。你会使用KCallable.call方法来调用被引用的参数。这个例子中,你需要提供一个单独的实参,42.如果你用错误数量的实参去调用函数,对比kFunction.call(),这将会抛出一个运行时异常:“IllegalArgumentException:Callable expects 1 arguments,but 0 were provided.”(IllegalArgumentException:Callable期望的是一个参数,但只提供了0个)。
然而,这种情况下(指报错),你可以用一个具体的方法来调用这个函数::foo表达式的类型是KFunction1< Int,Unit>,它包含了形参类型和返回类型的信息。1表达这个函数接收一个形参。你使用invoke方法通过这个接口来调用函数。它(上边foo的方法)接收固定数量的实参(这个例子中是一个),而且这些实参的类型对应着KFunction1接口的类型形参。你可以直接调用kFunction¹以:
import kotlin.reflect.KFunction2
fun sum(x:Int, y:Int) = x + y
>>> val kFunction: KFunction2<Int,Int,Int>=::sum
>>> println(kFunction.invoke(1,2)+kFunction(3,4))
10
>>> kFunction(1)
ERROR:No value passed for parameter p2现在你无法用数量不确定的实参去调用kFunction的invoke方法:这连编译都不能通过。因此,如果你有这样一个具体类型的KFunction,它的形参类型和返回类型是确定的,那么应该优先使用这个具体类型的invoke方法。call方法是对所有类型都有的的通用手段,但是它不提供类型安全性。
KFunctionN接口是如何定义的,又是在哪里定义的?
像KFunction1这样的类型代表了不同数量参数的函数。每一个类型都继承了KFunction并加上一个额外的成员invoke,它拥有数量刚好的参数。例如,KFunction2声明了operator fun invoke(p1:P1,p2:P2) : R,其中P1和P2代表着函数的参数类型,而R代表函数的返回类型。
这些类型称为 合成的编译器生成类型, 你不会在包kotlin.reflect中找到它们的声明。这意味着你可以使用任意数量参数的函数接口。合成类型的方式减小了kotlin-reflect.jar的尺寸,同时避免了对函数类型参数数量的人为限制。
你也可以在一个KProperty实例上调用call方法,它会调用该属性的getter。但是属性接口为你提供了一个更好的获取属性值的方法:get方法。
要访问get方法,你需要根据属性声明的方式来使用确定的属性接口。顶层值表述为KProperty0接口的实例,它有一个无参数的get方法:
var counter = 0
>>> val kProperty = ::counter
>>> kProperty.setter.call(21) //通过反射调用setter,把21作为实参传递
>>> println(kProperty.get()) //通过调用 “get” 获取属性的值。
21一个成员属性由KProperty1(描述)的实例表示,它拥有一个单参数的get方法。要访问该属性的值,就必须提供你需要的值所属的那个对象实例。下面这个例子在memberProperty变量中存储了一个指向属性的引用(Person::age);然后调用memberProperty.get(person)来获取属性具体person实例的这个属性的值。所以,如果memberProperty指向了Person类的挨个属性,memberProperty.get(person)就是动态获取person.age的值的一种方式:
class Person(val name: String, val age: Int)
>>> val person = Person("Alice",29)
>>> val memberProperty = Person::age
>>> println(memberProperty.get(person))
29注意,KProperty1是一个泛型类(描述)。变量memberProperty的类型是KProperty<Person,Int>,其中一个类型参数表示接收者的类型,而第二个类型参数代表了属性的类型。这样你只能对正确类型的接收者调用它的get方法;而memberProperty.get(“Alice”)这样的调用不会通过编译。
还有一点值得注意,只能使用反射(反射注意事项)访问定义在最外层或者类中的属性,而不能访问函数的局部变量。如果你定义了一个局部变量x并试图使用::x来获取它的引用,你会得到一个编译器的错误:“References to variables aren’ t supported yet”(现在还不支持对变量的引用)。
👇图展示了运行时你可以用来访问源码元素的接口的层级结构。因为所有的声明都能被注解,所以代表运行时声明的接口,比如KClass、KFunction和KParameter,全部继承了KAnnotatedElement。KClass既可以用来表示类也可以表示对象。KProperty可以表示任何属性,而它的子类KMutableProperty表示用var声明的可变属性。可以使用声明在KProperty和KMutableProperty中的特殊接口Getter和Setter,把属性的访问器当成函数使用——例如,如果你需要取回它们的注解。两个访问器的接口都继承了KFunction。简单起见,图中我们省略了像KProperty0这样的具体的属性接口。
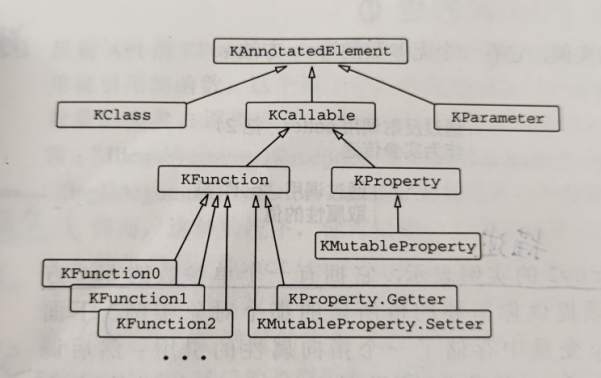
熟悉了Kotlin反射API的基础,下面研究JKid库是如何实现的。
10.2.2 用反射实现对象序列化
首先,回忆一下JKid序列化函数的声明:
fun serialize(obj:Any):String这个函数接收一个对象然后返回JSON表示法的字符串。它通过一个StringBuilder实例构建JSON结果。这个函数在序列化对象属性和它们的值同时,这个内容被附加到这个StringBuilder对象之中。我们把实现放在StringBuilder的扩展函数中,好让append的调用更加简洁。这样,你就不用限定符就可以方便地调用append方法:
private fun StringBuilder.serializeObject(x:Any){
append(...)
}把一个函数参数转化成一个扩展函数的接收者是Kotlin代码中的常见模式,我们会在下个章节继续讨论 。 注意serializeObject没有扩展StringBuilder的API。它(扩展)执行的操作在这个特殊的 上下文之外 毫无意义,所以它被标记成private,以保证它不会在其他地方使用。它被声明成扩展以强调这个特殊对象是代码块的主要对象,让这个对象用起来更容易。
结果,serialize函数把所有的工作委托给了serializeObject:
fun serialize(obj:Any):String = buildString{ serializeObject(obj) }在5.5.2节中,buildString会创建一个StringBuilder,并让你在lambda中填充它的内容。这个例子中,对serializeObject(obj)的调用提供了要填充的内容。
现在我们讨论一下序列化函数的行为。默认情况下,它将序列化对象的所有属性:基本数据类型和字符串将会被酌情序列化成JSON数值、布尔值和字符串值:集合将会被序列化成JSON数组;其他类型的属性将会被序列化成嵌套的对象。这些行为是可以通过注解定制的。
看看serializeObject的实现,在这里可以在真实的场景中观察反射API。
private fun StringBuilder.serializeObject(obj: Any){
val kClass = obj.javaClass.kotlin //获取对象的kClass
val properties = KClass.memberProperties //获取类的所有属性
properties.joinToStringBuilder(
this,prefix = "{",postfix = "}") {
prop -> serializeString(prop.name) //获取类的属性名字
append(":")
serializePropertyValue(prop.get(obj)) //获取属性值
}
}这个函数的实现应该很清晰:逐一序列化类的每一个属性。生成的JSON看起来会是这样:{prop1:value1,prop2:value2}。joinToStringBuilder函数保证属性与属性之间用逗号隔开。serializeString函数按照JSON格式的要求对特殊的字符进行转义。serializeString函数检查一个值是否是一个基本数据类型的值、字符串、集合或是嵌套对象,然后相应的序列化它的内容。
在前面的小节中,我们讨论过一个获取KProperty实例值的方式:get方法。在那个例子中,你使用过类型为KProperty1<Person,Int>的成员引用Person::age,它让编译器知道了接收者和属性值的确切类型。然而在这里例子中,确切类型是未知的,因为你列举了一个对象的类中的所有属性。因此,prop变量拥有类型KProperty1<Any,*>,而prop.get(obj)返回一个Any类型的值。你不会得到任何针对接收者的编译器检查,但是因为你传递的对象和获取属性列表的对象是同一个,接收者的类型是不会错的。
10.2.3 用注解定制序列化
在本章的前部分,你见过了定制JSON序列化过程的注解定义。实际上我们讨论过@JsonExclude、@JsonName和@CustomSerializer这几个注解。现在是时候看看serializeObject函数是如何处理这些注解的。
从@JsonExclude开始,这个注解允许你在序列化的时候排除某些属性。让我们研究一下应该如何修改serializeObject函数的实现来支持它。
(修改serializerObject来支持@JsonExclude) 回忆一下,你使用KClass实例的扩展属性memberProperties,来取得类的所有成员属性。但现在的任务变得更加复杂:使用@JsonExclude注解的属性需要被过滤掉(过滤有使用@JsonExclude注解的属性不要它)。我们来看看如何做到这一点。
KAnotatedElement接口定义了属性annotations,它是一个由应用到源码中元素上的所有注解(具有运行时的保留期)的实例组成的集合。(继承关系)因为KProperty继承了KAnnotationElement,可以用property.annotations这样的写法来访问一个属性的所有注解(使用property.annotations来获取一个属性的所有注解)。
但这里的过滤并不会用到所有的注解,它只需要找到那个特定在注解(@JsonExclude)。辅助函数findAnnotation完成了这个工作:
inline fun <reified T> KAnnotatedElement.findAnnotation():T?
= annotations.filterIsInstance<T>().firstOrNull()findAnnotation函数将返回一个注解,其类型就是指定为类型实参的类型,如果这个注解存在。它用到9.2.3节中我们讨论过的模式,让类型形参变成reified,以期把注解类作为类型实参传递。
现在可以把findAnnotation和标准库函数filter一起使用,过滤掉那些带@JsonExclude注解的属性:
val properties = kClass.memberProperties
.filter{it.findAnnotation<JsonExclude>() == null}下一个注解是@JsonName。我们把它的实现和使用它的例子重新放在这里作为提示:
annotation class JsonName(val name:String)
data class Persion{
@JsonName("alias") val firstName:String,
val age:Int
}这种情况下,你关心的不仅是注解存不存在,还要关心它的实参:被注解的属性在JSON中应该用的名称(属性在JSON中的名称)。幸运的是,findAnnotation函数可以帮上忙:
val jsonNameAnn = prop.findAnnotation<JsonName>() //取得@JsonName注解的实例,如果它存在的话
val propName = jsonNameAnn?.name ?: prop.name //取得它的“name” 实参或者备用的“prop.name”如果属性没有用@JsonName注解,jsonNameAnn就是null,而你仍然需要使用prop.name作为属性在JSON中的名称。如果属性用@JsonName注解了,你就会使用在注解中指定的名称而不是属性自己的名称。
(上述代码Person类中的两个属性) 我们来看一下事先声明的Person类的一个实例的序列化过程。在属性firstName序列化期间,jsonNameAnn包含了注解类JsonName对应的实例。所以jsonNameAnn?.name返回了非空的值“alias”,将会用作JSON中的键。但属性age序列化时,没有找到这个注解,所以属性名称age被用作JSON中的键。
我们目前为止所有讨论过的修改组合到一起,看看组合后形成的序列化逻辑实现。
/* 使用属性过滤序列化对象 */
private fun StringBuilder.serializeObject(obj:Any){
obj.javaClass.Kotlin.memberProperties
.filder{it.findAnnotation<JsonExclude>()==null} //判断是否有属性使用JsonExclude注解
.joinToStringBuilder(this,prefix="{",postfix = "}"){
serializeProperty(it,obj)
}
}现在用@JsonExclude注解的属性被过滤掉了。我们还把负责属性序列的逻辑抽取到了一个单独的serializeProperty函数。
/* 序列化单个属性 */
private fun StringBuilder.serializeProperty(
prop:KProperty1<Any,*>,obj:Any
){
val jsonNameAnn = prop.findAnnotation<JsonName>()
val propName = jsonNameAnn?.name ?:prop.name
serializeString(propName)
append(":")
serializePropertyValue(prop.get(obj))
}属性的名称根据之前讨论的@JsonName注解进行处理。
下一步,我们来实现剩下的注解@CustomSerializer。它的实现基于getSerializer函数,该函数返回通过@CustomSerializer注解注册的ValueSerializer实例。例如,如果像下面展示的这样声明Person类,并在序列化birthDate属性的时候调用getSerializer(),它会返回一个DataSerializer的实例:(描述)
data class Person(
val name:String,
@CustomSerializer(DataSerializer::class) val birthDate:Date
) 这里提示一下@CustomSerializer注解是如何声明的,帮助你更好的理解getSerializer的实现:
annotation class CustomSerializer(
val serializerClass: KClass<out ValueSerializer<*>>
)下面实现getSerializer函数。
/* 取回属性值的序列化器 */
fun KProperty<*>.getSerializer():ValueSerializer<Any?>?{
val customSerializerAnn = findAnnotation<CustomSerializer>() ?: return null
val serializerClass = customSerializerAnn.serializerClass
val valueSerializer = serializerClass.objectInstance ?: serializerClass.createInstance()
@Suppress("UNCHECKED_CAST")
return valueSerializer as ValueSerializer<Any?>
}它的KProperty的扩展函数,因为属性是这个方法要处理的主要对象(接收者)。它调用了findAnnotation函数取得一个@CustomSerializer注解的实例,如果实例存在。它的实参serializerClass指定了你需要获取那个类的实例。
处理作为@CustomSerializer注解的值的类的对象(Kotlin的单例)的方式,是这里最有趣的一部分。它们都用KClass类表示。不同的是,对象拥有非空值objectInstance属性,可以用它来访问为object创建的单例实例。例如,DateSerializer被声明成了object,所以它的objectInstance属性存储了DateSerializer的单例实例。你将用这个实例序列化所用对象,而不会调用createInstace。
如果KClass表示的是一个普通的类,可以通过调用createInstance来创建一个新的实例。这个函数和java.lang.Class.newInstance类似。
最终,你可以在serializerProperty的实现中用上getSerializer。下面是这个函数的最终版本。
/* 序列化属性,支持自定义序列化器 */
priavte fun StringBuilder.serializerProperty(
prop: KProperty1<Any,*>, obj:Any
){
val name = prop.findAnnotation<JsonName>()?.name ?: prop.name
serializeString(name)
append(": ")
val value = prop.get(obj)
val jsonValue = prop.getSerializer()?.toJsonValue(value) //如果自定义序列化器存在就为属性使用它
?: value //否则像之前那样使用属性值
serializePropertyValue(jsonValue)
}serializeProperty通过调用序列化器的toJsonValue,来吧属性值转换成JSON兼容的格式。如果属性没有自定义序列化器,它就使用属性的值。
现在你已经见过了这个库JSON序列化部分的实现,我们的话题将转移到解析和反序列化。反序列化部分需要更多的代码,所以我们不会审查所有代码,但会看到实现的结构,并解释反射是如果用来反序列化对象的。
10.2.4 JSON解析和对象反序列化
让我们从故事的第二部分开始:实现反序列化的逻辑。首先,回忆一下API,它和序列化用到的API相似,包含一个单独的函数:
inline fun <reified T:Any> deserialize(json: String) :T使用它的例子(以下源代码在JKid库中)
data class Author(val name: String)
data class Book(val title: String, val author: Author)
>>> val json = """{"title": "Catch-22", "author": {"name": "J. Heller"}}"""
>>> println(deserialize<Book>(json))
Book(title=Catch-22, author=Author(name=J. Heller))你要被反序列化的对象和类型作为实化类型参数传给deserialize函数并拿回一个新的对象实例。
(对象反序列化要求) JSON反序列化是比序列化跟困难的任务,因为它涉及解析JSON字符串输入,还有使用反射访问对象的内部细节。JKid中的JSON反序列化器使用相当普通的方式实现,由三个主要阶段组成:词法分析器(通常被称为lexer)、语法分析器或解析器,以及反序列化组件本身。
词法分析把一个字符组成的输入字符串切分成一个由标记组成的列表。这里有两类标记:代表JSON语法中具有特殊意义的字符(逗号、冒号、花括号和方括号)的字符标记;对应到字符串、数字、布尔值以及null常量的值标记。左花括号({)、字符串值(“Catch-22”)和整数值(42)是不同标记的例子。
解析器通常负责将无格式的列表转换为结构化的表示法。它在JKid中的任务是理解JSON的更高级别的结构,并将各个标记转换为JSON中支持的语义元素:键值对、对象和数组。
JsonObject接口跟踪当前正在被反序列化的对象或数组。解析器在发现当前对象的新属性(简单值、复合属性或数组)时调用对应的方法。
/* JSON解析器回调接口 */
interface JsonObject {
fun setSimpleProperty(propertyName: String, value: Any?)
fun createObject(propertyName: String): JsonObject
fun createArray(propertyName: String): JsonObject
}这些方法中的参数propertyName接收到了JSON键。因此,当解析器遇到一个使用对象作为值的author属性时,createObject(“author”)方法会被调用。简单值属性被报告为setSimpleProperty调用,实际的标记值作为value实参传递给这次调用。JsonObject实现负责创建属性的新对象,并在外部对象中存储对它们的引用。
下图,展示了反序列化一个样本字符串时,词法和语法分析每一阶段的输入和输出。再一次,语法分析将输入字符串切分成标记列表,然后句法分析(解析器)处理这个标记列表,并在每个有意义的新元素上调用JsonObject中适当的方法。

然后,反序列化器为JsonObject提供一种实现,逐步构建相应类型的新实例。它需要找到类属性和JSON键(上图中title、author、和name)之间的对应关系,并构建嵌套对象的值(author)的实例。在这之后,它才可以创建一个最终需要的类的新实例(Book)。
JKid库打算使用数据类,因此,它将从JSON文件加载的所有名称-值的配对作为参数传递给要被反序列化的类的结构方法。它不支持在对象实例创建后设置其属性。这意味着JSON中读取数据时它需要将数据存储在某处,然后才能构建该对象。
在创建对象之前保存其组件的要求看起来与传统的构建器模式相似,区别在于构建器通常用于创建一种特定类型的对象,并且解决方案需要完全通用。我们在这个实现中使用了一个有趣的词语种子(Seed)。在JSON中,你需要构建不同类型的复合结构:对象、集合和map。ObjectSeed、ObjectListSeed和ValueListSeed类负责构建适当的对象、复合对现象的列表,以及简单值的列表。而map的构造就作为练习留给你了。
基本的Seed接口继承了JsonObject,并在构建过程完成后提供了一个额外的spawn方法来获取生成的实例。它还声明了用于创建嵌套对象和嵌套列表的createCompositeProperty方法(它们使用相同的底层逻辑通过种子来创建实例)。
/* 从JSON数据创建对象的接口 */
interface Seed : JsonObject {
fun spawn(): Any?
fun createCompositeProperty(
propertyName: String,
isList: Boolean
): JsonObject
override fun createObject(propertyName: String) = createCompositeProperty(propertyName, false
)
override fun createArray(propertyName: String) = createCompositeProperty(propertyName, true)
}你可以认为spawn就是返回结果值的build方法的翻版。它返回的是为ObjectSeed构造的对象,以及为ObjectListSeed或ValueListSeed生成的列表。我们不会详细讨论列表是如何反序列化的。我们将注意力集中于创建对象,它更复杂并有助于通用的思路。
但再次之前,我们先来研究一下deserialize的主要功能,它完全反序列化一个值的所有工作。
/* 顶层反序列化函数 */
fun <T : Any> deserialize(json: Reader, targetClass: KClass<T>): T {
val seed = ObjectSeed(targetClass, ClassInfoCache())
(Parser(json, seed))
return seed.spawn
}整个解析过程是这样的,一开始你会创建一个ObjectSeed来存储反序列化对象的属性,然后调用解析器并输入字符流json传递给它。当达到输入的数据的结尾时,你就可以调用spawn函数来构造最终对象。
现在我们聚焦ObjectSeed的实现,它存储了正在构造的对象的状态。ObjectSeed接收了一个目标类的引用和一个classInfoCache对象,该对象包含缓存起来的关于该类属性的信息。这个缓存起来的信息稍后将被用于创建该类的实例。ClassInfoCache和ClassInfo是我们将在下一节讨论的辅助类。
/* 反序列化一个对象 */
class ObjectSeed<out T : Any>(targetClass: KClass<T>, val classInfoCache: ClassInfoCache) : Seed {
private val classInfo: ClassInfo<T> = classInfoCache[targetClass] //缓存需要创建targetClass实例的信息
private val valueArguments = mutableMapOf<KParameter, Any?>()
private val seedArgements = mutableMapOf<KParameter, Seed>()
private val arguments: Map<KParameter, Any?> //构建一个从构造方法参数到它们的值的映射
get() = valueArguments + seedArgements.mapValues { it.value.spawn() }
override fun setSimpleProperty(propertyName: String, value: Any?) {
TODO("Not yet implemented")
val param = classInfo.getConstructorParameter(propertyName)
valueArguments[param] =
classInfo.deserializeConstructorArgument(param, value) //如果一个构造方法参数的值是简单值,把它记录下来。
}
override fun createCompositeProperty(propertyName: String, isList: Boolean): Seed {
val param = classInfo.getConstructorParameter(propertyName)
val deserializeAs =
classInfo.getDeserializeClass(propertyName) //如果有的话加载属性DeserializeInterface注解的值
val seed = createSeedForType(
deserializeAs ?: param.type.javaType, isList
) //根据形参的类型创建一个ObjectSeed或者CollectionSeed
return seed.apply { seedArgements[param] = this } //并把它记录到seedArgument中
}
override fun spawn(): T =
classInfo.createInstance(auguments) //传递实参map,创建targetClass实例作为结果
}ObjectSeed构建了一个构造方法形参和它们的值之间的映射。这用到了两个可变的map:给简单值用的valueArguments和给复合属性用的seedArguments。当结果开始构建时,新的实参通过setSimpleProperty调用被添加到valueArguments,通过createCompositeProperty调用被添加到seedArguments。新的复合种子被添加时状态是空的,然后被来自输入流的数据填充。最终,spawn方法递归地调用每个种子的spawn方法来构建所有嵌套的种子。
注意,spawn的方法体中arguments调用是怎样启动递归的复合(种子)实参的构建过程的:auguments自定义的getter调用seedArguments中每一个元素的spawn方法。createSeedType函数分析形参的类型并根据形参是那种集合来创建ObjectSeed、ObjectListSeed或者ValueListSeed。我们把它实现的剩下部分交给你自己去研究。接下来,我们来看看ClassInfo.createInstance函数是如何创建targetClass的实例的。
10.2.5 反序列化的最后一步:callBy()和使用反射创建对象
最后一部分你需要理解的就是ClassInfo类,它创建了作为结果的实例,还缓存了关于构造方法参数的信息。ObjectSeed用到了它。但在我们一头扎进实现细节之前,我们先来看看通过反射来创建对象的API。
你已经见过了KCallable.call方法,它调用函数或者构造方法,并接收一个实参组成的列表。这个方法很多情况下都很好用,但它有一个限制:不支持默认参数。这种情况下,如果用户试图用带默认参数的构造方法来反序列化一个对象,绝对不想这个实参还需要在JSON中说明。因此,你需要使用另外一个支持默认参数的方法:KCallable.callBy。
interface KCallable<out R>{
fun callBy(args:Map<KParameter,Any?>):R
}这个方法接受一个形参和它们对应值之间的map,这个map将被作为参数传给这个方法。如果map中缺少一个形参,可行的话它的默认值将会被使用。还有一点特别方便的是,你不必按照顺序来写入形参:可以从JSON中读取名称-值的配对,找到每个实参名称队形的形参,把它的值写入map中。
有一点需要注意的是取得正确的类型。args map中值的类型需要跟构造方法的参数类型想匹配,否则你将得到一个IllegalArgumentException。这对算数运算来说很特别重要:你需要知道参数接收的是一个Int、一个Long、一个Double,还有一个其他的基本数据类型,并把来自JSON的算数值转成正确的类型。可以使用KParameter.type属性来做到这一点。
这里的类型转换是通过ValueSerializer接口完成的,这个接口和定制序列化时用的ValueSerializer接口是同一个。如果属性没有@CustomSerializer注解,你会根据它的类型获取标准的实现。
/* 根据值类型取得序列化器 */
fun serializerForType(type: Type): ValueSerializer<out Any?>? = {
when (type) {
Byte::class.java -> ByteSerializer
Int::class.java -> IntSerializer
Boolean::class.java -> BooleanSerializer
//...
else -> null
}
}/* Boolean值的序列化 */
object BooleanSerializer : ValueSerializer<Boolean> {
override fun fromJsonValue(jsonValue: Any?): Boolean {
if (jsonValue !is Boolean) throw JKidException("Boolean expected")
return jsonValue
}
override fun toJsonValue(value: Boolean) = value
}callBy方法给了你一种调用一个对象的主构造方法的方式,需要传给它一个形参和对应值之间的map。ValueSerializer机制保证了中的值拥有正确的类型。现在我们看看如何调用这个API。
ClassInfoCache皆在减少反射操作的开销。回忆一下用来控制序列化和反序列化过程的注解(@JsonName和@CustomSerializer),它们是用在属性上,而不是形参上。当你反序列化一个对象时,你打交道的是构造方法参数而不是属性:要获取注解,你需要先找到对应的属性。在读取每个(JSON)键值对的时候都执行一次这样的搜索将会极其缓慢,所以每个类只会做一次这样的搜索并且把信息缓存起来。下面是ClassInfoCache的完整实现。
/* 缓存的反射数据的存储 */
class ClassInfoCache {
private val cacheData = mutableMapOf<KClass<*>, ClassInfo<*>>()
@Suppress("UNCHECKED_CAST")
operator fun <T : Any> get(cls: KClass<T>): ClassInfo<T> = cacheData.getOrPut(cls) { ClassInfo(cls) } as ClassInfo<T>
}这里使用了在9.3.6节中我们讨论过的模式: (回去看) 在map中存储的时候去掉类型信息,但get方法的实现保证了返回的ClassInfo< T >拥有正确的类型实现。注意getOrOut的用法:如果mapCacheData已经包含了一个cls的值,你就返回这个值。否则,调用传递进来的lambda,它会计算出这个键对应的值并存储在map中,然后返回它。
ClassInfo类负责按目标类创建新实例并缓存必要信息。为了简化代码,我们省略了一些函数和默认初始化器的代码。还有,你可能注意到生产代码会抛出一个带有丰富信息的异常(这也是你的代码应该采用的良好模式),来替代这里的 !! 。
/* 构造方法的参数及注解数据的缓存 */
class ClassInfo<T : Any>(cls: KClass<T>) {
private val constructor = cls.primaryConstructor!!
private val jsonNameToParamMap = hashMapOf<String, KParameter>()
private val paramToSerializerMap =
hashMapOf<KParameter, ValueSerializer<out Any?>>()
private val jsonNameToSerializerClassMap =
hashMapOf<String, Class<out Any>?>()
init {
constructor.parameters.forEach { (cls, it) }
}
fun getConstructorParameter(propertyName: String): KParameter =
jsonNameToParam[propertyName]!!
fun deserializeConstructorArgument(
param: KParameter, value: Any?
): Any? {
val serializer = paramToSerializer[param]
if (serializer != null) return serializer.fromJsonValue(value)
validateArgumentType(param, value)
return value
}
fun createInstance(arguments: Map<KParameter, Any?>): T {
ensureAllParametersPresent(arguments)
return constructor.callBy(arguments)
}
}在初始化时,这段代码找到了每个构造方法参数对应的属性并取回了它们的注解。它把这些数据存储在三个map中:jsonNameToParamMap说明了JSON文件中的每个键对应的形参,paramToSerializerMap存储了每个形参对应的序列化器,还有jsonNameToDeserializeClassMap存储了指定为@DeserializeInterface注解的实参的累,如果有的话。然后ClassInfo就能根据属性名称提供构造方法的形参,并调用使用形参的代码,这些代码中这个形参将作为形参和实参之间map的键使用。
cacheDataForParameter、validateArgumentType和ensureAllParametersPresent是这个类的私有函数。下面是ensureAllParametersPresent的实现,可以自己浏览其他函数的代码。
/* 验证需要的参数被提供了 */
private fun ensureAllParametersPresent(arguments: Map<KParameter, Any?>) {
for (param in constructor.parameters) {
if (arguments[param] == null && !param.isOptional && !param.type.isMarkedNullable) {
throw JKidException("Missing value for parameter ${param.name}")
}
}
}这个函数检查你是不是提供了全部需要的参数的值。注意这个反射API是如何帮助你的。如果一个参数有默认值,那么param.isOptional是true,你就可以为他省略一个实参;反之默认值就会被使用。如果一个参数类型是可空的(param.type.isMarkedNullable会告知你这一点),null将会被作为默认的参数值使用。对所有的形参来说,你都必须提供对应的实参:否则就会抛出异常。反射缓存保证了只会搜索一次那些定制反序列化过程的注解,而不会是JSON数据中出现的每一个属性都执行搜索。
10.3 小结
- Kotlin中引用注解的语法和Java几乎一摸一样。
- 在kotlin中可以让你应用注解的目标的范围比Java跟广,其中包括了文件和表达式。
- 一个注解的参数可以是一个基本数据类型、一个字符串、一个枚举、一个类应用、一个其他注解类的实例,或者前面这些元素组成的数组。
- 如果单个Kotlin声明产生了多个字节码元素,像@get:Rule这样指定一个注解的使用点目标,允许你选择注解如果应用。
- 注解类的声明是这样的,它是一个拥有主构造方法且没有类主体的类,其构造方法中所有参数都被标记成val属性。
- 元注解可以用来指定(使用点)目标、保留期模式和其他注解的特性。
- 反射API让你在运行时动态的列举和范围一个对象的方法和属性。它拥有许多接口来表示不同种类的声明,例如类(KClass)、类(KFunction)等。
- 要获取一个KClass的实例,如果类是静态已知的,可以使用ClassName::class;否则,使用obj.javaClass.kotlin从对象实例上取得类。
- KFunction接口和KProperty接口都继承了KCallable,它提供了一个通用的call方法。
- KCallable.callBy方法能用来调用带默认参数值的方法。
- KFunction0、KFunction1等这种不同参数数量的函数可以使用invoke方法调用。
- KProperty0和KProperty1是接收者数量不同的属性,支持用get方法取回值。KMutableProperty0和KMutableProperty1继承了这些接口,支持通过set方法来改变属性的值。
补充
字段和属性
属性和字段的区别
属性(property),通常可以理解为get 和 set 方法。
字段(field),通常叫做 类成员,或者 类变量 ,有时也叫 域 ,理解为 数据成员,用来承担数据的。
属性和字段详解
字段(field)
类成员(字段field),通常在类中定义成员变量例如:

解释为:FacebookUser类拥有成员变量nickname,有一个字段 nickname。
字段一般用于承担数据,所以为了数据的安全性,一般设置为私有的。
字段和常量描述的类的数据(域),当这些数据的某些部分不运行外界访问时,根据”对象封装“原则,应该尽量避免将类的字段以公有方式提供给外部。除啦final修饰的常量。
属性(property)
属性只局限于类中方法的声明,并不与类中其它成员相关,数据JavaBean范畴:

这是一个属性,一个字段。
总结:属性是对字段的封装,供外部访问。通常属性将对应的私有字段通过封装成公共属性,以便于外界访问和修改。
计算属性
计算属性通过覆盖字段get或者set运算符来定义的,
class Book{
val name
get() {}
}表达式
是指可以被求值的代码。
例如
int result = add(x + 1,y)x + 1 作为表达式传递了数值
int result = add(if(x==1),y)这段语句在 c 中是没有办法作为表达式的。
Kotlin this表达式
为了表示当前的 接收者 使用 this{:.keyword} 表达式:
- 在类的成员中,this{:.keyword}指的是当前对象
- 在扩展函数或者带接受者的函数字面值中,this{:.keyword}表示在点左侧的接收者参数。
函数引用
函数引用 是kotlin引入的一个功能。使用(::)表示对函数的引用。它属于函数类型。
代码
val sum:(Int,Int) -> Int = {x,y -> x +y}sum 是一个函数类型的变量,lambda表达式执行了相加的操作。
fun applyOp(x: Int, y: Int, op: (Int, Int) -> Int): Int = op(x, y)applyOp 是一个接受三个参数的函数,第三个参数是lambda类型。可以用下面的返回调用这个函数:
applyOp(2,3,sum)
----------
5即高阶函数可以作为一个类型赋值给变量,也可以作为另一个函数的参数。
函数引用:函数可以是一个 lambda
将上述代码变换成函数时就需要使用到函数引用了。
上述的lambda表达式,可以用纯函数的形式(也叫具体函数):
fun sum(x: Int, y: Int) = x + y实现效果是一样的,区别在于不再需要使用变量来保持对函数的引用,但是这样需要对applOp函数要做一些修改
applyOp(2,3,::sum)
----------
5这些算是 函数引用 的大致概念。同时函数引用也是可以赋值给变量的。
val sumLambda: (Int, Int) -> Int = ::sum
applyOp(2, 3, sumLambda)lamnda 表达式 与 匿名内部类的区别
- lambda 表达式只能为函数式接口创建实例;匿名内部类可以为任意接口创建实例 – 不管接口包含多少抽象方法,只要匿名内部类是实现所有的抽象方法即可。
- lambda 表达式只能为函数式接口创建实例;匿名内部类可以为抽象类甚至普通话类创建实例;
- lambda 表达式的代码不允许调用接口中定义的默认方法;匿名内部类实现的抽象方法的方法体允许调用接口中定义的默认方法。
链式调用
Reified实化类型参数
背景:
Java中泛型是在JDK1.5版本后引入的,但集合Collection实在JDK1.2版本时引入的,现在看到的List,是在泛型出现后加入的,那么JDK1.2之前就直接用LIst(java中俗称原生态类型)表示。在为了兼容之前的版本Java采用所谓的伪泛型,伪泛型有一个特征就是泛型擦除,表示泛型类型信息在编译时期会被抹除掉,包括你是List还是List在运行时它们都是一样,那都是List类型,泛型类型信息已经被抹除掉了。
Kotlin中的形参和实参
ps:
什么才是泛型擦除
ps:
序列化和反序列化
序列化:对象转化成字节的过程。
反序列化:字节转化成对象的过程。
it关键字
it关键字是由函数自动生成的形参名字,可以直接访问当前函数的形参。
val method: (String) -> String = {
"$it 返回了生成的it形参"
}
println(method("it -- "))
it -- 返回了生成的it形参匿名函数的返回类型推断
val methodDouble = { doubleValue: Double ->
doubleValue
}
val methodString = { stringValue: String ->
stringValue
}
println(methodDouble(9.02))
println(methodString("这是String类型"))
9.02
这是String类型kotlin会自动推断返回类型。
split 拆分函数
用来拆分字符串,并按照拆分字符拆分。返回值是个List< String>。
fun main() {
val testString = "split,and,string"
val splitString = testString.split(",")
for (i in splitString)
println(i)
}
replace替换函数
功能:替换字符。
可以接收一个正则表达式来作为匹配字符的条件,它返回String类型。
这里将条件字符转换成了小写和单词。
fun main() {
val sourceString = "AADDCCEEFFLLIINN22331"
val replaceString = sourceString.replace(Regex("[CEF1]")) {
when (it.value) {
"C" -> "c"
"E" -> "e"
"F" -> "f"
"1" -> "one"
else -> it.value
}
}
println(replaceString)
}
run函数
场景
用于let,with函数的场景中。run函数弥补了let函数在函数体中必须使用it参数代替对象,run函数可以同with函数一样省略,直接访问公有属性和方法,同时弥补了with传入对象判空问题,在run函数中又可以像let函数一样判空处理。
run函数只接受一个lambda函数作为参数,以闭包形式返回,并以最后一行或者指定return的表达式作为返回值。
object.run{
// 函数体
}.run{
// 以上条返回值作为参
}内联函数also
描述
let函数用来处理不为空的场景。
结构上同let一样区别是返回值不一样,let以闭包形式返回,以返回函数体最后一行的值,为空时返回Unit类型为默认值。而also函数返回调用对象本身。
object.also{
// 函数体
}
fun main() {
val string: String? = null
val stringTest: String? = "test"
println(string?.also { print("非空") })
println(stringTest?.also { print("非空") })
}

takeIf 函数
描述
对一个对象进行判断,使用判断表达式在表达式为true时返回对象本身,false时返回null。可以对返回的对象进行链式调用。
fun main() {
val test = "testString"
// false时返回null
println(test.takeIf { it.length > 20 }.apply { println("判断字符串对象test为false时返回null") })
println()
// 表达式true时返回对象本身
println(test.takeIf { it.length > 0 }.apply { println("判断字符串对象test为true时返回字符串本身") })
}
takeUnless 函数
描述
对一个对象判断,表达式为true时返回null,不为true为false时返回对象本身。可以对返回对象进行链式调用。
fun main() {
val test = "testString"
// false时返回对象本身
println(test.takeUnless { it.length > 20 }.apply { println("使用takeUnless时判断为false时执行") })
println()
// 表达式true时返回null
println(test.takeUnless { it.length > 0 }.apply { println("使用takeUnless时判断为true时执行") })
}
List集合的getOrElse函数与getOrNull函数
描述
返回给定位置的元素,如果超过超出范围调用getOrNull函数的defaultValue函数参数返回结果。
源码
/**
* Returns an element at the given [index] or the result of calling the [defaultValue] function if the [index] is out of bounds of this list.
*/
@kotlin.internal.InlineOnly
public inline fun <T> List<T>.getOrElse(index: Int, defaultValue: (Int) -> T): T {
return if (index >= 0 && index <= lastIndex) get(index) else defaultValue(index)
}fun main() {
val listTest = listOf<String>("one", "twp", "three")
// 打印第一个位置
println(listTest.getOrElse(0, defaultValue = { "超出边界时发送" }))
// 超出范围的
println(listTest.getOrElse(4, defaultValue = { "超出边界时发送" }))
}
getOrNull描述
返回给定位置的元素,超出边界返回“null”
源码
/**
* Returns an element at the given [index] or `null` if the [index] is out of bounds of this list.
*
* @sample samples.collections.Collections.Elements.getOrNull
*/
public fun <T> List<T>.getOrNull(index: Int): T? {
return if (index >= 0 && index <= lastIndex) get(index) else null
}fun main() {
val listTest = listOf<String>("one", "twp", "three")
// 打印第一个位置
println(listTest.getOrNull(0))
// 超出范围的返回空,并判断打印输出
println(listTest.getOrNull(4))
println(listTest.getOrNull(4) ?: "返回为null超出了边界")
}

List集合中mutator函数和contains函数、Predicate类
mutator函数
能够修改可变列表的函数有统一的名字:mutator函数
contains函数
如果字符串中包含[other]字符串作为子字符串,则返回 ‘true’。
Predicate接口
函数时接口。此接口用于筛选数据,通过给定的若干项的流作为满足的项。
removeIf函数
删除当前项目中满足Predicate接口条件的所有元素。在抛出错误时将异常返回给调用者。删除成功时返回‘true’。
import java.util.function.Predicate
fun main() {
val mutableList = mutableListOf<String>("one", "two", "three")
// mutator函数
mutableList += "添加"
println(mutableList)
// removeIf删除满足条件的元素
mutableList.removeIf(Predicate { it.contains("one") })
println(mutableList)
}

伴生对象
companion伴生对象
可以做什么?
可以直接在代码中调用且只加载一次。它与Java中的static静态修饰符类似。
fun main() {
CompaionClass.testCompanionFun()
println(CompaionClass.testCompanionVal)
}
class CompaionClass{
companion object{
val testCompanionVal="伴生对象的变量"
fun testCompanionFun(){
println("使用伴生对象的静态方法")
}
}
}
Kotlin 运算符重载
让运算符为用户定义的类工作
Kotlin中的operator将调用它相应运算符成员函数。a+b运算符可转换为a.plus(b)
Kotlin只能重载一组特定的运算符。
案例用运算符重载拼接两个字符串
fun main() {
val p1 = TestClass("wang")
val p2 = TestClass(name = "li")
var sum = p1 + p2
println(sum)
}
data class TestClass(var name: String) {
// 拼接完返回String类型
operator fun plus(p1: TestClass): String {
var string = name + p1.name
return string
}
}代数数据类型
什么是代数数据类型
代数:能够代表数字的符号。
例如x+1=10中的x就代表代数。还可以通过运算符获得新的代数y*9=z。那么将这些代数或者数字转换成类型,以及通过这些类型所产生的类型就叫做代数数据类型。
例子:
fun main() {
println("${getArea(Shape.Circle(5.0))}") //获得圆形面积
println("${getArea(Shape.Rectangle(5.0, 5.0))}") //获得矩形面积
println("${getArea(Shape.Triangle(5.0, 5.0))}") // 获得三角形面积
}
sealed class Shape {
//由于 sealed 密封类默认是open修饰的所以可以继承父类成为子类
class Circle(val radius: Double) : Shape()
class Rectangle(val width: Double, val height: Double) : Shape()
class Triangle(val base: Double, val height: Double) : Shape()
}
Shape密封类,这里将圆形等图形面积所需要的变量抽象为代数数据类型(ADT)。 因为这些形状都属于几何类型Shape所以可以抽象为代数数据类型。
引用: